
A technical framework for mitigating the MBU problem in FPGA based on a three-level, low-overhead, systematic approach
Commercial off-the-shelf FPGAs are considered to be the only way to solve the ever-increasing demand for processing power in current space applications. Due to their sensitivity to multi-bit flipping, special design reinforcement techniques are needed for single-particle effects in space applications. A fault-tolerant technology framework based on user logic layer, configuration memory layer and control layer is proposed. At the user logic level, a new low-overhead FTR strategy is proposed for user logic error detection. At the configuration memory level, a dynamic partial reconfigurable strategy based on modules and frames is proposed to handle configuration memory errors. At the control level, the Xilinx ZYNQ system-on-chip FPGA is targeted, and its embedded hard-core processor is used to save and restore circuit states based on checkpoint and rewind system. The entire fault-tolerant technology framework was tested for fault injection in the LEON3 open source processor with 7-stage flow. The test results show that 99.997% of the injected faults are obtained with an increase of 85% of LUT resources and 125% of trigger resource usage conditions. Corrected in time.
0 Preface
Commercial chips have more processing power than space chips, but are susceptible to single-particle effects. Many scholars have carried out related research work, mainly through the continuous global configuration refresh to alleviate the erroneous data bits in the configuration memory. Based on this, it proposes to reconfigure circuits in specific areas based on Dynamic Partial Reconfiguration (DPR) technology, which reduces configuration time and improves efficiency.
Another possible method of processing is to perform error detection and coding correction within the configuration memory. Usually, single-bit error correction and double-error detection (SEC-DED) can be detected, but it cannot cope with multi-bit flipping. (Multiple bit upset, MBU) case [5]. There are two methods for fault-tolerant design of user logic circuits. One is to implement Triple Modular Redundancy (TMR) design. The main disadvantage is that the cost is high; the other method is to perform error detection only in the user logic circuit. Using Duplication With Comparison (DWC) technology, all logical resources are replicated and comparators are added to compare results. In order to further reduce resource utilization, it is proposed to perform error detection in the user logic circuit while saving and restoring the circuit state by adding a hierarchy.
According to the above analysis, the current soft error techniques for FPGAs mainly involve the user logic layer, configuration memory layer, and control layer. Different technologies can target different scenarios, and there is no targeted optimization for specific applications between resources and power consumption. . Therefore, this paper proposes a systematic framework for mitigating the MBU problem in FPGA based on three-level and low overhead, and then simulates the fault injection of the open source LEON3 processor soft core through the Xilinx ZYNQ platform.
1 Three-level soft error mitigation technology framework
With the minimum resource overhead, the lowest power consumption, and the shortest processing delay time as the optimization goals, a systematic solution to the commercial off-the-shelf FPGA space application was proposed through effective coordination at the user logic level, configuration memory level, and control level. The soft error mitigation technology framework for the MBU capacity problem faced is based on the Xilinx ZYNQ SoC (System-on-Chip) fault-tolerant technology framework as shown in Figure 1.
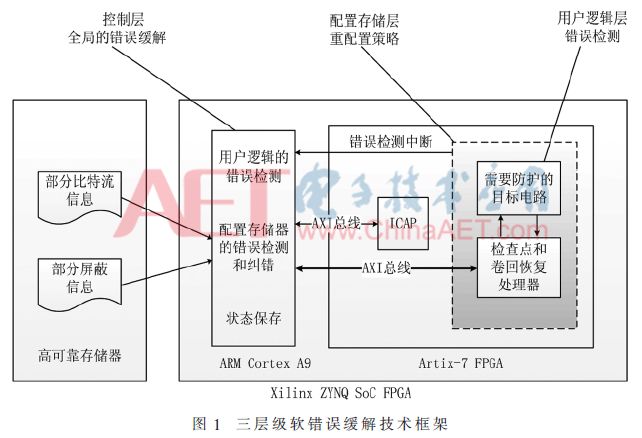
The redundancy strategy chosen by the user logic layer directly affects the upper layer architecture. For example, the use of TMR technology for soft error mitigation requires more than 200% of resource overhead. It is not suitable for space applications where resources and power consumption are strictly limited. It is necessary to reduce the area and power consumption as the optimization goal. Potentially reduce delays.
The delay and power consumption of the strategy for configuring the memory layer selection mainly depend on the reconfigured granularity and error correction capability. The latter mainly depends on reading and writing the entire configuration data or just the redundant information of the built-in error correction coding. Back.
At the control level, the main considerations are delay and power consumption. Check points and rollback systems can be used. The main design parameters are the checkpoint setting cycles.
2 user logic layer
At the user logic level, there are two general methods for error detection: one is DWC technology, which is a full hardware backup strategy; the other is Temporal Redundancy (TR) technology. The combinational and sequential logic in Figure 2 has two independent paths that can be compared at the output of each flip-flop so that the detection delay time is the shortest. In Figure 3, the TR technology is used. Only the sequential logic is redundant. Usually, the basic circuit uses one clock, and a clock with a delay time d is provided to the redundant triggers. This keeps the entire circuit's hold time constraint worst-case. Is d, the settling time constraint is unchanged. This strategy can be used to simultaneously detect single-event flipping in sequential logic and single-event transients (SET) in combinational logic when the combined logic resource overhead is low.
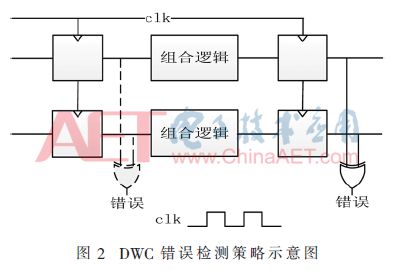
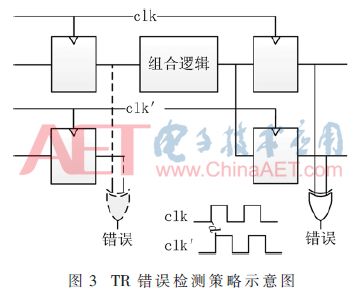
The delay time d must first ensure that all SETs in the combinational logic can be detected and therefore must be greater than the maximum duration of SET. As the process size decreases, the SET duration increases, the SET duration is 0.2-0.8 ns for the 30 MeV.cm2/mg LET and 130 nm processes, the Xilinx ZYNQ uses 28 nm process technology, and the delay is 2 ns. about. At the same time, as the delay d increases, more delay wiring resources need to be added, which may easily lead to competition and risk reduction and greatly reduce the maximum clock operating frequency. Therefore, the use of the TR strategy is very limited for delays up to 2 ns.
In order to improve the scope of application of the TR strategy, the Forward Temporal Redundancy (FTR) strategy shown in FIG. 4 is proposed. The main difference from the TR is that the delay is reversed, and the clock phase used for the trigger comparison is reversed. In advance, the circuit's hold time has not changed, but the settling time constraint is more severe. Therefore, the maximum propagation delay from the clk to clk' clock domain is reduced by d. FTR is a low-power and low-area solution with no risky competition conditions.
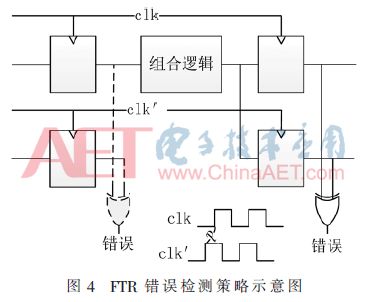
3 Configure the memory layer
There are three different granular operations for the reconfiguration or refresh of the configuration memory. As shown in FIG. 5, the first one is a complete reconfiguration or refresh, and the efficiency is relatively low; the second is a partial reconstruction based on a module, and a suitable circuit is used. Limited to the Partially Reconfigurable Region (PRR); the third is the best operation granularity, ie, based on the partial reconstruction of the frame, the frame is based on the smallest unit of the address table, including 101 on the Xilinx ZYNQ platform. The bit word, each frame is accessed through the corresponding Frame Address Register (FAR), provides the fastest error detection capability.
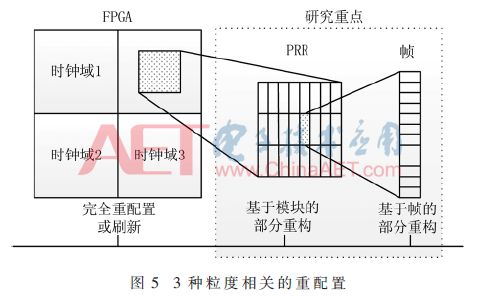
In order to improve the efficiency of detection and correction, a module-based and frame-based DPR method is proposed to be used at the configuration memory layer: First, the resource location of the user logic circuit is accurately located, and the bit stream information of the corresponding part is extracted at the same time, and then quick error detection is implemented. . Frame-based readback can be used to detect all internal PRR errors. Bitstream signals include not only configuration bits but also user memory cells, which can change state during circuit operation. These corresponding bits must be masked by the .mask file during readback.
The above method is particularly suitable for the case where the user circuit can be divided into multiple independent small PRRs. The more accurate the location of the area is, the smaller the PRR is, the less the delay is, and the more stable the circuit performance is.
At the same time, the hardware error can be handled through the bitstream relocation technology, and only a small-capacity external memory is required to store part of the bitstream.
Another common configuration memory protection strategy is the Xilinx-provided IP core, which monitors and corrects the entire configuration memory. This core requires 900 lookup tables and 700 flip-flops without resource fault tolerance in Xilinx ZYNQ. Larger.
Xilinx FPGAs support a variety of refresh and configuration approaches. In order to minimize latency and improve system reliability, ICAP interfaces are preferred.
4 control layer
The control layer mainly completes two tasks: coordination processing and state preservation. The coordination processing function is mainly divided into two parts, one part is related to the user logic layer, and it is used to handle the errors detected in the user logic; the other part is related to the configuration storage layer, which is used to configure memory to correct errors. State save is specifically designed to support checkpoint and rollback operations. Figure 6 shows a complete algorithm description based on the Xilinx ZYNQ platform.
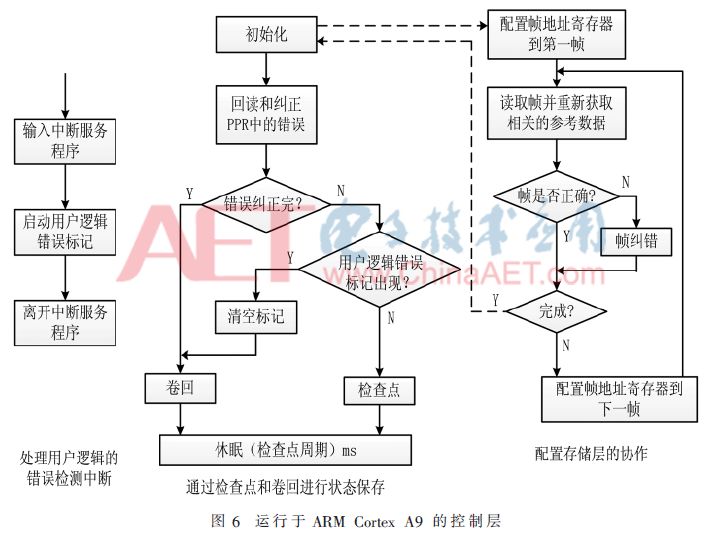
Checkpoints and rollback operations can be implemented in three ways. The first is to use the FPGA's BRAM to store the status information. To ensure that these information will not be changed, proper protection mechanisms must be used. Usually, the built-in SEC-DED-EDAC is used, and the MBU cannot be used. The second method is to process at a higher level, using the readback capture feature, and the processor retrieves the state information directly from the configuration logic unit. However, this method requires a special layout design, or it may cause large delay overhead. The last method is to transfer through the internal data bus, such as AXI, which can be shared in the module design of multiple PRRs. Similar to the second method, the reacquired status data can be coded using software with higher error correction capability. Error correction, or stored in a single-immune immune memory to ensure the correctness of the data, these data can also be passed back to support the rewind operation.
According to the trade-off between delay and power consumption, the cycle parameters of an optimized checkpoint are selected, and the processor executes the task according to the time cycle. This parameter needs to be adjusted according to the application requirements. For hard real-time systems, the checkpoint period can be reduced to zero, and the minimum delay boundary is determined by the readback time. The use of a hard-core processor for control reduces the use of single-particle-sensitive FPGA resources and improves overall system reliability.
5 Test results using open source LEON3 processor cores
This article uses the open source LEON3 processor soft core as a basic program for testing. Its status unit mainly includes the program counter, register file and data memory. It needs to be protected through checkpoint and rollback operations. Tested on the Xilinx ZYNQ XC7Z010-1CLG400C platform.
Quantify and compare different redundancy strategies at the user logic level. Table 1 shows the comparison results. As can be seen from the table, the FTR strategy has the best results, low power consumption, low area overhead, and is suitable for space applications, achieving the best balance between performance and cost. Due to the stricter establishment of time constraints, the maximum operating frequency that an FTR strategy can run is greater than that of TR.

Figure 7 shows the resource overhead comparison required to implement all mitigation techniques. It can be seen from the figure that the use of FTR strategy adds only 63% of combinational logic and 101% of sequential logic resources.
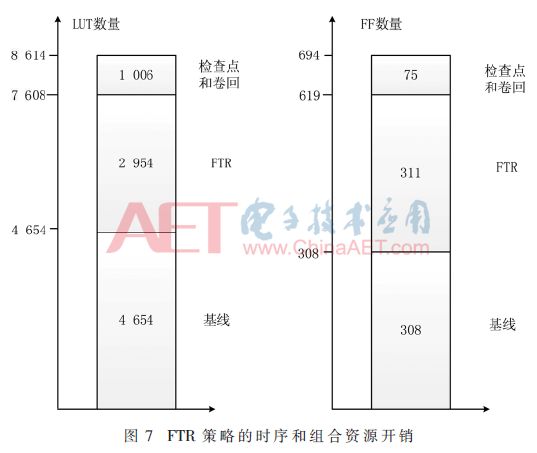
In the configuration memory layer, the location is determined more accurately, and the advantages of the FTR are better reflected. The error in one frame can be corrected in only 34 μs. The LEON3 processor includes 2640 frames, and the whole PRR can be read back within 90 ms. , By optimizing the speed of the ICAP port can further reduce the time, up to 300 MHz.
At the control level, status information is stored in program counters, register files and data memory, protected by checkpoints and roll-back operations, and connected to hard-core processors via the AXI bus. This strategy is sensitive to the amount of data that needs to be transmitted. Usually, the on-chip data memory is only a few kilobytes. Larger capacity needs are provided by off-chip memory, and off-chip memory can use complex detection, error correction, and coding.
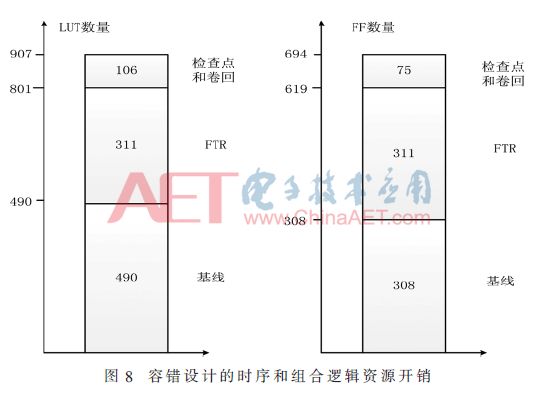
Figure 8 shows 22% of the combinatorial logic and 24% of the timing logic overhead used for checkpoint and volume-return handlers.
The effectiveness of the entire software mitigation technical framework was verified through fault injection. First read the address information corresponding to the frame, then flip one of the bits, and finally write back the frame data, resulting in an error. The effective use of bit information can be found through the .ebd and .ll files generated by Xilinx, and the test results show that the 99.997% injected soft errors are corrected.
6 Conclusion
In order to meet the area and power consumption requirements of a low-cost, high-performance space application processing platform, an optimization model based on three levels of power consumption, area, reliability, and delay characteristics was proposed. Using the soft core of the LEON3 open source processor as a benchmark program, the 85% of combinatorial logic and 125% of sequential logic resource overhead are used to achieve redundancy and state preservation, which is better than a pure DWC system. Through the simulation experiment of fault injection, it is verified that the framework can effectively correct 99.997% of soft errors and have the mitigation capability of MBU.

About this project
ADVANCED SAFE CHARGING: The USB-C MacBook Pro Charger Power Adapter combines advanced safety features and premium fire-resistant materials with built-in protection against overheating, overcharging, overcurrent, and overvoltage.Fast Charge with PD 3.0: The USB C charger features a Thunderbolt 3 USB C port for full-speed charging, charging a 16-inch MacBook Pro in just 1 hour and 30 minutes. (Note input: AC 100-240V-1.5A(1.5A), 50-60Hz, output: 20.5V=4.7A, 15V=3A, 9V=3A or 5.2V=2.4A.
Wide Compatibility: Macbook Charger is compatible with Mac Pro 16 15 14 13", Mac Air 13", i-Pad Pro 11"/12.9", and also compatible with other USB-C enabled devices. Such as laptops, cameras, smart watches, mobile phones, tablets, game consoles, headphones, Nintendo Switch, etc.
GREAT ALTERNATIVE USB-C CHARGER: This compact USB C laptop charger is designed with a foldable plug for easy portability and convenient home/office and outdoor charging.
What you get: USB C Charger Add a free 6.6" USB-C to USB-C charging cable, compatible with Macbook Pro, Mac book Air, iPad Pro, it's more sturdy, super durable, tangle-free, with a lifespan of over 10000 Second-rate.
usb c charger for macbook,macbook usb c charger,usb c macbook adapter,usb c macbook power adapter
Shenzhen Waweis Technology Co., Ltd. , https://www.szwaweischarger.com