
Explain the YOLO algorithm in a concise language
YOLO algorithm, the English full name is You Only Look Once, the direct English full name can find the paper, and the author also open source code on github. It should be noted that this tweet is about yolo v1 and there is an upgraded version.
As the name implies, this algorithm can recognize all objects only by looking at the picture. This algorithm can detect objects in real time, which can reach 40 frames per second, and the speed is very fast. So how do you get started with this algorithm? I believe that you have seen a lot of articles about the YOLO algorithm, so I am not going to go deep into the algorithm here, but try to explain this fascinating algorithm in a concise language.

The biggest difference from other tweets is that I will show you how to make a dataset from a practical perspective and how to make a computer recognize a specific object.
Let's take a look at how the effect I achieved is. First of all, I found the blue cup on my desk and collected more than two hundred pictures of my own cup. In order to reduce the workload, I replaced all the data of the car with the data set of the water cup. After a dozen hours of training, the effect is as follows:

How to achieve it? First of all, I think you have to "understand" this algorithm first, at least you have to understand how it is implemented, what is the principle, what is the input and output. In order to learn this algorithm, I also spent a lot of time to read the author's papers and code. I think the paper cooperation code is a good way to learn. The code can be very clear to understand how it implements this algorithm.
The core of this algorithm is that it divides the picture into 7*7 grids. Note that this 7*7 grid does not cut a picture into 49 small blocks, but rather a grid corresponds to an output. It may feel a bit abstract, let's look at the picture first.

For example, in the above picture, there are a total of 49 grids. The task of each grid is to determine whether the center point of the object falls on the grid. If it falls on its own grid, then the grid is good. Will report to the system. Suppose the red grid marked in the above figure is named as a small grid, then the small grid finds that there is a dog here, so it reports to the system: I have a dog here, and then the system asks: How wide is the dog? The small grid seems a bit awkward, but according to its experience, the small grid can probably guess, so he answered the system: the dog is about 100 pixels wide and 250 pixels high. At this point, the task of the small grid is basically completed, the small grid is only one of the 49 grids, and the other grids are the same. So the system collected the opinions of 49 grids and then got the picture below.

In fact, 49*2=81 prediction boxes can appear in this picture, which means that no grid can have two predictions for the target, so up to 81 prediction boxes can appear. As you can see in the figure, there are a lot of useless boxes, and adjacent grids may have similar results, so we can filter a part of the prediction box by maximal value suppression. Then you can get the results of the figure below.

But believe me, even if you have fully understood what I said above, you may not be able to understand the code at once. When I read the code, I found that although the code is not much, the logic is clear, but there are some details. Hard to understand. Then let me take a look at it!
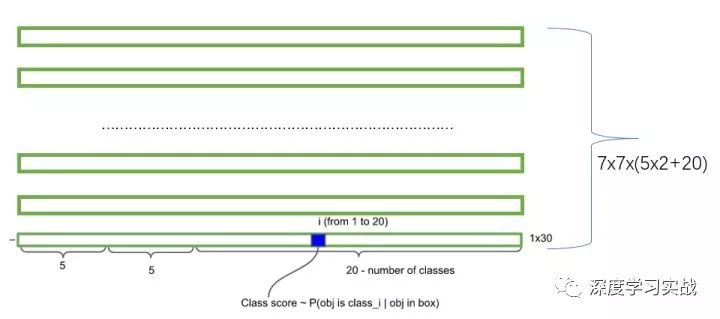
The more important code is mainly in pasal_voc.py, config.py, yolo_net.py and train.py. The code to load the data is in pasal_voc.py. The code is not very difficult, but one thing to note is that the label of a picture is actually a 7*7*25 matrix. The composition of a 25 vector is like this: first place It is 0 or 1, indicating whether there is an object, then the next four digits are the information of the bounding box, that is, (x, y, w, h), and the rest is the one-hot encoding table category. The predicted result is 7*7*30 because two boxes are to be predicted.
Another quintessence is the definition of its loss function, which calculates the mean square error for each predicted value, but the degree of punishment is not the same.
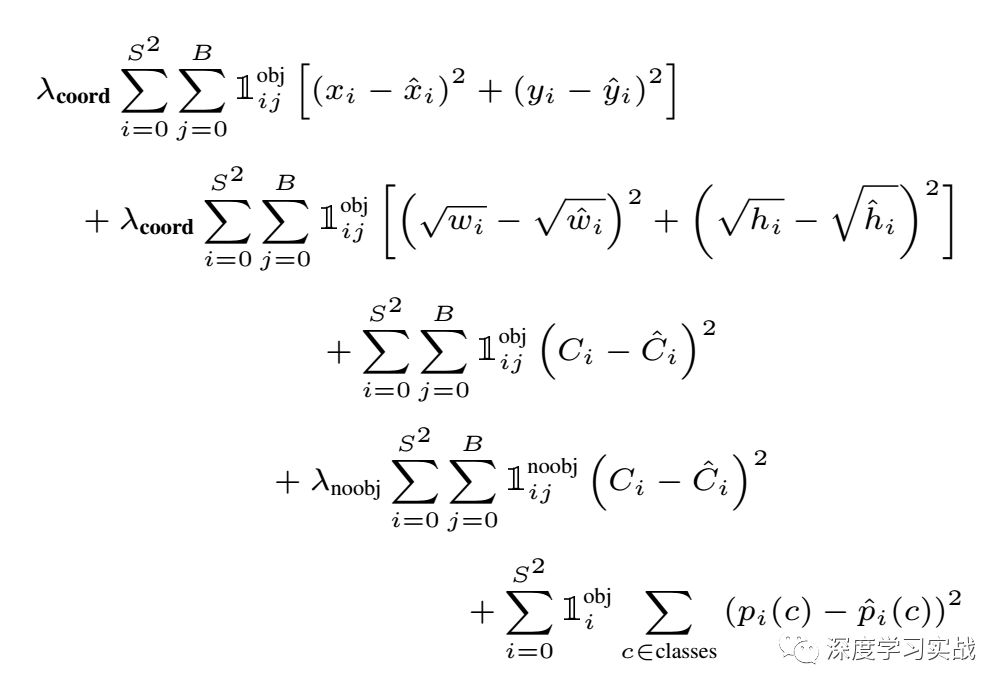
Where λcoord = 5.0, λnoobj = 1.0, λclasses = 2.0, but this set of numbers is not known from the small series, it may be a set of optimal solutions obtained from a large number of tests, or it may be from mathematical formulas Let's figure it out. In fact, there are a lot of small details that are difficult to describe. If you want to explain a small detail, you will have to countless details, so I suggest you use the code to understand the details.
After you have already understood the code, it is easy to achieve the effect at the beginning of the article. Then I will explain my thoughts and processes. The most important thing is to do it yourself. After you have studied its dataset, you will find that the annotation of this dataset is an xml file, and each image corresponds to an xml file. When you collect the data set, you can do the data set markup, but the format of the simplest xml file is as follows:

This is the annotation in my dataset, and the simplest annotation that can satisfy the code. I wrote a program myself to help me complete the markup, but I recommend that you use other people's annotation tools, because after all, others have already written it. There is no need to repeat the wheel.
This is a labeling tool, but I have never used it, but the description should be compliant. After doing the image annotation, how do you want to modify its data set? It’s hard to stick in a piece of paper. Of course you can do this, but the workload is very big. Ok, then give it to the computer to solve it. I made a judgment when loading the dataset. If there is a car in this image, I will not load the data. Specify a path to load the dataset we have made.
Findcar = 0for obj in objs: cls_ind = obj.find('name').text.lower().strip() if cls_ind == 'car': findcar = 1 break
The next step is to think about how to solve it. When you solve this problem and can train, if there is no accident, you should be able to get the same result as me, I wish you good luck!
Aspire Vape pen, Manufacture Aspire Vaporizer, Aspire Vape pod
Shenzhen Xcool Vapor Technology Co.,Ltd , https://www.szxcoolvape.com