
From the perspective of computer vision, we have thoroughly explained the past, present and future of augmented reality (AR)
Lei Feng network (search "Lei Feng network" public concern) : Author of this article Linghai Lin, the chief scientist of Brightwind Taiwan Information Technology.
Disclaimer: The purpose of this article is mainly to introduce concepts and technology science, and far from rigorous academic papers. Dear academia friends, please keep your consistent attitude of being tolerant, friendly, and full of energy. Do not offer opinions that are not related to praise. A detailed and rigorous introduction to AR is recommended by Professor Wang Yongtian's Introduction to Augmented Reality.
1. From reality to augmented realityAugmented Reality (AR) and Virtual Reality (VR) concepts have been around for decades. However, VR/AR has appeared in the technology media to attract the attention of all parties. . In this section we briefly introduce the two concepts and their history, while clarifying their differences.
First of all, let's think about it: What is reality? The problem is very profound in philosophy. Plato, an ancient Greek thinker, said, “Oh, pull away, and return to the computer world where everyone depends on raising a family.†Using the saying goes, we define reality as “seeing is trueâ€. To be more specific, the reality we are concerned with is the perception of the real world by the visual system presented to the human visual system. In simple terms, it is a real-world image.
The above definition clearly gives the enterprising computer cattle people a back door: if the images are generated in some way, as long as they are realistic enough, can they fool human eyes and even the entire brain? It makes sense that this is not the prototype of the Matrix. This virtual reality, no suspense is the definition of virtual reality (VR). Of course, the current technological capabilities are far from achieving the fascinating sense of immersion in the Matrix. In fact, from the earliest VR prototype, the virtual reality 3D personal theater Sensorama (1) invented by Morton Helig in 1962, to the recent wind of Oculus, the immersive sense brought by virtual reality technology is always in a kind of user initiative. The state of trust. Of course, this state is not a problem for many applications, so there are all kinds of VR products and capital-fighting VR predators and rookies.
So, is Augmented Reality (AR) a trick?
I often receive zealous friends, "Your company's VR is awesome." While vanity is satisfied, as a rigorous technical worker, I am actually very embarrassed. Many times I really want to say: Honey, we do AR, AAAAA R! Going forward, let's cite the definition of Wikipedia:
"Augmented reality (AR) is a live direct or indirect view of a physical, real-world environment whose elements are augmented (or supplemented) by computer-generated sensory input such as sound, video, graphics or GPS data. As a result, The technology functions by enhancing one's current perception of reality."
Please pay attention to the "physical, real-world environment" in the definition. That is, R in AR is a real R. In contrast, R in VR is a copycat version. Then the concept of augmentation of A is more imaginary: in general terms, all those who can add additional information to R are counted. In addition to various fancy things superimposed on real-time images like in HoloLens, practical systems such as real-time superimposed lane lines in the ADAS, indication arrows displayed in the head-in display of the auxiliary production system, etc. can be counted. Again, the information inside the AR is superimposed on the real scene instead of the virtual scene (VR). An interesting niche research direction is to superimpose the contents of a part of a real scene into a virtual scene. The scientific name is Augmented Virtualization (AV).

The example in Figure 2 may better reflect the difference between AR and VR. The top shows the typical VR device and the VR image received by the human eye, and the bottom is the AR device and AR image. In this set of examples we can see that VR completely isolates people from the real world, while AR does the opposite. The advantages and disadvantages of AR and VR are not here. Of course, if you are wise, you don't like to be blinded by virtual illusions, right? Also worthy of mention is the prediction of Digi-Capital's market prospects: By 2020, AR/VR's market size will total 150 billion US dollars, of which AR accounts for 120 billion and VR 300 billion.
From another point of view, they also have a clear similarity. They all interact with humans through computers. Therefore, they all need the ability to generate or process images and present them to human eyes. Way. The former is a very different place between AR and VR, VR is based on virtual generation, and AR is based on processing of reality. In terms of image presentation, AR and VR are basically the same, which is why it is difficult for people outside of China to distinguish between the two. In short, the difference between VR and AR is:
VR is approaching reality; AR is beyond reality.
Next we mainly discuss AR, focusing on the different parts of AR and VR. So how did AR develop? It is generally believed that the originator of AR is the optically transmissive helmet display (STHMD) invented by Professor Ivan Sutherland of Harvard University in 1966, which makes the combination of virtual and real. The term augmented reality was first proposed by Thomas P. Caudell, a Boeing researcher, in the early 1990s. In 1992, two early prototype systems, Virtual Fixtures virtual help system and KARMA machinist repair help system were proposed by Louis Rosenberg of the US Air Force and S. Feiner of Columbia University.

Many of the early AR systems were used in industrial manufacturing maintenance or similar scenarios, which were cumbersome and rough (as opposed to current systems). This aspect is due to the constraints of computing power and resources at the time, and the development of algorithmic technology on the other hand is not yet in place. At the same time, mobile digital imaging equipment is far from popular to individual users. After that, with the rapid development of these areas, AR applications and research have also made great progress. Particularly worth mentioning is the ARQuake system developed by Bruce Thomas et al. in 2000 and Wikitude launched in 2008. The former has pushed AR into the mobile wearable area, and the latter has settled AR directly on the mobile phone side. As for the recently launched HoloLens and the mysterious Magic Leap, it is even more concerned about AR than ever before.

From below, we will introduce AR from the perspective of software technology and intelligence understanding.
2. Vision Technology in ARAugmented Reality Technology Process
According to Ronald Azuma's 1997 summary, augmented reality systems generally have three main characteristics: virtual reality, real-time interaction, and three-dimensional registration (also known as registration, matching, or alignment). Nearly two decades have passed, AR has made great progress, and the focus and difficulties of system implementation have also changed. However, these three elements are basically indispensable in the AR system.
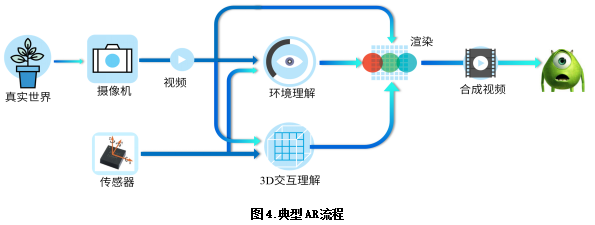
Figure 4 depicts the conceptual flow of a typical AR system. Starting from the real world, after digital imaging, the system uses the image data and sensor data together to perceive the three-dimensional world, and at the same time obtain an understanding of the three-dimensional interaction. The purpose of 3D interactive understanding is to tell the system what to "enhance". For example, in an AR-assisted maintenance system, if the system recognizes a mechanic's page-turning gesture, it means that the next page to be superimposed on the real image should be the next page of the virtual manual. In contrast, the purpose of 3D environment understanding is to tell the system where to "strengthen." For example, in the above example, we need a new display page that looks exactly the same in space as it used to, in order to achieve a strong sense of realism. This requires the system to have a precise understanding of the real world surrounding it in real time. Once the system knows the content and location to be enhanced, it can perform a combination of virtual and real, which is usually done through the rendering module. Finally, the synthesized video is delivered to the user's visual system and achieves the effect of augmented reality.
In the technological process of AR, the collection of data (including images and sensors) is relatively mature, and the display and rendering technologies have also made considerable progress. Relatively speaking, the accurate understanding of the environment and interaction in the middle is the current bottleneck. Smart classmates will surely think that if this part of the middle uses basic virtual generated content, can it not? Congratulations on coming to the lively VR world: It is said that since 2015, hundreds of VR companies have emerged in the country. There are hundreds of VR glasses to do. If you don't use a few VR terms, you're embarrassed and say hello. Of course, this article discusses AR, the environment and interactive understanding based on multimodality (simply image + sensor) in the middle of the above picture. It is two fields full of bright or dark pits, enough to make many fakes. The warriors retired.
Difficulties and opportunities for environmental and interactive understanding
Then, what kind of bleak and dripping pit will the real warriors face? Let's share some common pit types together:
Environmental pits: It is said that most of the brain cells in humans are used to process and understand the visual information acquired by the eyes, and many things that we have been able to understand and perceive at a glance have benefited from our powerful brain processing capabilities. The impact of various environmental changes on visual information We can not only easily deal with, but sometimes we can use it. For example, our cognitive ability is quite robust to changes in light illumination; for example, we can use shadows to reverse the three-dimensional relationship. And these are just pits or pits for computers (more precisely computer vision algorithms). Understand this kind of pit, it is not difficult to understand why many seemingly beautiful demos are practical and so sad. Possible reasons include changing the light, changing the shape, changing the texture, changing the posture, changing the camera, and background. Changed, the prospects changed; shadows, obstructions, noises, disturbances, distortions, etc. What is even more sad is that these factors that affect the effectiveness of the system are often hard to detect in our human visual system, so that small white users often express doubts about our ability to work and generate impulses to get started. In general, changes in the imaging environment often pose great challenges to computer vision algorithms and AR, so I refer to related pits collectively as environmental pits.
Academic pits: The understanding of the environment and the reconstruction of interactions is basically a category of computer vision. Computer vision is a field that has been accumulated for half a century, and AR-related academic achievements can be measured in tons. For example, if you are interested in tracking, the top-level conference papers (such as CVPR) that contain “tracking†in the title of light articles can have dozens of articles each year. To exaggerate one point, each piece has pits, and the difference is only shades of light. Why is this? Well, in this case, we must send a CVPR. We have to think new, strong theory, complicated formulas, good results, and not too slow (Emma, ​​I'm easy, I). However, the procedure is really difficult to fit the data. It is also difficult to keep limitations (notice plurals). This is not to say that these academic achievements are useless. On the contrary, it is these scholarly academic advancements that have gradually given birth to the progress of the field. The point is, from the point of view of practical solutions, academic papers, especially new ones, must be careful of the settings and some extra information, and think about whether the algorithm is sensitive to light and whether it may be in mobile phones. The end reaches real time and so on. The simple suggestion is: For a paper on computer vision, viewers with no relevant experience should watch carefully with a mature audience with relevant training.
God pit: Who is God? Of course it is the user. God's pit, of course, is so creative that it often stirs the developer's desire for a cry. For example, God said that to be able to distinguish the gender of the video, 80% accuracy, 1 million. Wow, you are not touched by the tears (God God), easy to use a variety of stylish methods to get more than 10% easily. However, when delivered, God said that your system can't recognize the gender of our little baby? Oh my God, are you excited to cry again. Compared with environmental pits, CV's algorithms often require assumptions and strong assumptions. then what should we do? God is always right, so the only way is to educate God as soon as possible so that he is more correct: you need to be as hospitable as possible and user science as soon as possible and as clearly as possible to define the needs of prevention. If not enough, what should we do? God, please add a little more money.
In fact, there are other types of pits, such as open source code pits, which are not detailed here. Well, why is there so much to follow in such an area full of misery? The most important reason is the huge application prospects and money. To be small, many specific application areas (such as games) have successfully introduced the elements of AR; to say the big things, the ultimate form of AR may fundamentally change the current non-natural human-computer interaction model (please brainstorm Microsoft Win95's success and now HoloLens) . The pits mentioned above, in many applications, may be avoided or may not be filled in so deeply. For example, in an AR game, the content of the game needs to be superimposed on the tracked Marker, and the particularity of the game makes it difficult to ensure the accuracy of the tracking (well, it is actually the algorithm is not done enough), resulting in an impact on the user experience. Jitter. In this case, a simple and effective way is to make the content to be superimposed dynamic, so that the user will not feel unpleasant jitter. There are many examples of similar actual combat, some of which are resolved from the rendering end, and more are for the specific use cases to do optimization at the algorithm level. In general, a good AR application is often a combination of algorithm engineering, product design, and content creation.
Well, parallel imports speak too much. Here we begin to talk about technology. Mainly to track the registration, the first is the core importance of these technologies in the AR, secondly, in other aspects I actually do not understand (see me more modest, huh, huh).
AR tracking registration technology development
Three-dimensional registration is the core technology of linking virtual reality. There is no one. Roughly speaking, the purpose of registration in the AR is to make geometrically accurate understanding of the image data. In this way, the positioning problem of the data to be superposed is determined. For example, in the AR-assisted navigation, if you want to "stick" the navigation arrow on the road (as shown in Figure 5), you must know where the road is. In this example, every time the camera of the mobile phone acquires a new frame of image, the AR system first needs to locate the road surface in the image, specifically to determine the position of the ground in a certain predefined world coordinate system, and then The arrow to be posted is virtually placed on the ground, and the arrow is drawn in the corresponding position in the image through the geometric transformation associated with the camera (through the rendering module).

As mentioned before, 3D tracking registration presents many technical challenges, especially given the limited information input and computing capabilities of mobile devices. In view of this, in the development course based on visual AR, it has experienced several stages from simple positioning to complex positioning. The following briefly introduces this development process, and more technical details are discussed in the next section.
Two-dimensional code: Like the WeChat two-dimensional code principle that is widely used by people today, the main function of two-dimensional code is to provide a stable and fast identification mark. In AR, in addition to identification, two-dimensional codes also provide part-time functions that provide easy tracking and positioning of planes. For this reason, the two-dimensional code in AR is simpler than the two-dimensional code in general for accurate positioning. Figure 6 shows an example of an AR QR code.

Two-dimensional pictures: The unnatural artifacts of two-dimensional codes greatly limit its application. A very natural extension is the use of two-dimensional pictures, such as banknotes, book posters, photo cards, and so on. The smart white friends must have discovered that the QR code itself is a two-dimensional picture. Why does it not use the two-dimensional code method directly on the two-dimensional picture? Oh, it's sauce purple: The reason why the QR code is simple is because the pattern above it is designed so that the visual algorithm can quickly identify the positioning. The general two-dimensional image does not have such good properties, but also needs a more powerful algorithm. . Also, not all 2D images can be used for AR positioning. In extreme cases, a solid-colored picture without any patterns cannot be positioned visually. In the example of FIG. 7 , two cards are used to locate the virtual fighters of two battle points.

Three-dimensional objects: The natural extension of two-dimensional pictures is a three-dimensional object. Some simple regular three-dimensional objects, such as cylindrical cola cans, can also be used as carriers for the combination of virtual and real. Slightly more complicated three-dimensional objects can also be treated or broken down into simple objects in a similar way, as is the case in industrial repairs. However, for some specific non-regular objects, such as human faces, there are many algorithms that can accurately align in real time due to years of research accumulation and massive data support. However, how to deal with common objects remains a huge challenge.
3D environment: In many applications we need to understand the geometry of the entire surrounding 3D environment. For a long time and within a predictable period of time, this has always been a challenging problem. In recent years, the application of three-dimensional environment perception in the fields of unmanned vehicles and robots has achieved successful results, which makes people full of paralysis in their application in AR. However, compared to unmanned vehicles and other application scenarios, the a priori computing resources and scenarios that can be used in AR are often overstretched. Affected by this, there are two obvious ideas for the development of three-dimensional scene understanding in AR. The first is the combination of multiple sensors, but the customization of applications. The combination of two ideas is also a common method in practice.
Among the above-mentioned technologies, the identification and tracking technology of two-dimensional codes and two-dimensional pictures has basically matured and has been widely used. The technical development goals are mainly to further improve stability and broaden the scope of application. In contrast, the recognition of three-dimensional objects and three-dimensional scenes still has a lot of space for exploration. Even if the current popular HoloLens shows amazing tracking stability, there are still many opportunities for improvement from the perspective of perfection. .
3, monocular AR recognition trackingDue to the importance of identifying tracking, the following briefly describes two-dimensional image tracking and three-dimensional environmental understanding in AR. The technology of two-dimensional codes has matured and applications are more limited. The technology of three-dimensional object recognition is roughly between two-dimensional pictures and three-dimensional scenes, so it is not lazy to mention it.
AR Tracking of 2D Planar Objects
In general, the tracking of two-dimensional planar objects in an AR can be attributed to the following problem: given a template picture R, the three-dimensional accurate position of the picture (relative to the camera) is detected at all times in the video stream. For example, in the example of FIG. 8 , R is a picture of a renminbi that is known to be realized. The video is acquired in real time from a mobile phone and is usually denoted as It (representing a video image obtained at time t). What needs to be obtained is R in It. Geometric Geometry (usually including three-dimensional rotation and translation), denoted as Pt. In other words, the template picture R can be attached to its position in the picture It through the three-dimensional transform represented by Pt. The purpose of tracking the results is also very clear, since we know the gesture Pt, we can use a dollar image to superimpose the video in the same attitude to replace the renminbi, so as to achieve more than 6 times the show off effect. Well, the example is not so tacky, but a solemn video is superimposed.

So how does the tracking and positioning in the above example work? There are roughly two mainstream methods. One is the direct method (sometimes called the global method), and the other is the indirect method. Oh, it's called the keypoint-based method.
Direct method: "Direct" in the direct method means to directly use the optimization method to find the best goal, namely Pt. There are three main elements involved here:
(1) How to define good and bad, (2) Where to find Pt, (3) How to find it.
For (1) , an intuitive approach is: suppose that the template map transforms a small area on the corresponding image It according to the pose Pt, then this area can be exported an image T, T (after normalization) should be and template R The better you look, the better.
For (2) , we can find Pt in all possible poses. However, this strategy is obviously very time consuming. Considering the limited changes in the adjacent image frames in the video, we usually look around at the last moment (usually recorded as Pt-1). As for how to find it, this translates into an optimization problem. Simply put, it is to find a Pt in a neighborhood of Pt-1 so that the image blocks T and R are the most similar through Pt. Of course, the actual operation of the above three parts are all stress. For example, in (1), whether the T and R are similar may consider the change of illumination, and (2) how to define the neighborhood of the attitude space and the reasonable neighborhood size.
(3) What kind of optimization algorithm is used to combat local extreme interference as much as possible and not too time-consuming. Different processing methods produce different tracking algorithms. One of the typical representative tasks is the ESM algorithm and some of its variants.
ESM is the abbreviation of Efficient Second-order Minimization. It was derived from the work published by Benhimane and Malis at IROS in 2004. The algorithm uses the reconstructed error squared as a measure of the similarity between R and T, and then reconstructs the Lie Group for posture space to make the search step more rational. A fast algorithm for order approximation. The structure of this algorithm is clear, each module can be independently extended easily, so on the basis of it derived a lot of improved algorithms, usually for different adjustments in the practical scene (such as dealing with strong light or motion blur).
Control Point Method: The control point-based method has become the mainstream method in the industry due to its real-time efficiency. The method of the control point class does not directly optimize the attitude Pt, but calculates the Pt by the control point matching method. A typical flow of the control point method is shown in Figure 9. The basic starting point is to use a special point (usually a corner point) in the image to establish a mapping between the template R and the video image It, establish a system of equations through the mapping, and then solve the pose Pt. For example, if the template is a picture of a character, then we do not need to match all points on the face when locating in the video, but we can quickly locate it through some control points (eyes, nose, mouth, etc.).
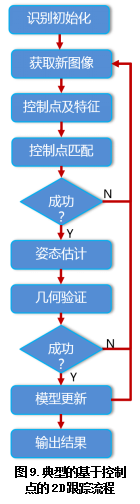
A slightly more mathematical explanation is this: Since pose Pt is controlled by several parameters (generally 8), one way to solve Pt is to get a system of equations, say 8 linear equations, then we can Find Pt. What about these equations? We know that the role of Pt is to change the template R into the image It, that is, each point in R can get its position in the image after a transformation determined by Pt. Then, in turn, if we know that a point in the image (such as the corner of the eye) and the template are the same point (that is, they match), we can use the pair of matching points to give two equations (X, Each one of the Y coordinates, such a point is the so-called control point. When we have enough pairs of control points, we can solve the pose Pt.
To sum up, the control point method includes three main elements: (1) control point extraction and selection, (2) control point matching, and (3) attitude solution.
The basic requirements of the control point are: first, to be able to stand out from the surrounding environment (reduce the ambiguity in position), and second, to appear frequently and steadily (easy to find). The corner points in various images are therefore debuted, with various PKs. Well-known SIFT, SURF, FAST and so on. It should be noted that the rankings mentioned above are in order: According to their capabilities, the better they are, the better they are in terms of speed. Actual application can be decided according to the user's model. So, can these points be used after extraction? No, in general, we need to make trade-offs: one is to remove unused points (outliers), the other is to make the selected points as uniform as possible to reduce unnecessary errors, and to prevent too many points from bringing too much Follow-up calculations.
The purpose of the control point matching is to find a matching point pair between the control point sets of the two images (nose tip to nose tip, eye corner to corner of the eye). Usually this is done collaboratively by the similarities between control points and spatial constraints. Simple methods have close-to-matching, and the complex is basically bipartite matching or two-dimensional assignment. After the matching is completed, the attitude Pt can be solved: Since the number of points usually used is much larger than the minimum requirement (for stability), the number of equations here is much larger than the number of unknown variables, so solutions such as least squares are here Will come in handy.
The above three steps may appear clearly different at first, but they are often intertwined when actually used. The main reason is that it is difficult to guarantee accurate control points. Useful and reliable control points are often mixed with all kinds of genuine and fake cottages, so it is often necessary to round-trip iterations between three steps, such as selecting control points using methods such as RANSAC to get most of the attitudes. Compared with the direct method, the basic algorithm framework of the control point method is relatively mature, and the details of the engineering implementation largely determine the final effect of the algorithm.
The advantages and disadvantages of these two methods are slightly different according to the specific implementation, and can be summarized as follows: Â

The advantages and disadvantages of the two types of methods are clearly complementary. Therefore, a natural idea is the combination of the two. There are also different variants of the specific methods. This is not ridiculous here.
3D Environment AR Tracking
The dynamic real-time understanding of the three-dimensional environment is the most active issue of current AR in technical research. Its core is the recent fiery "Simultaneously Localization And Mapping" (SLAM, Simultaneously Localization And Mapping), which also plays a central role in the fields of unmanned vehicles, drones, and robots. The SLAM in the AR is much more difficult than in other areas, mainly because the computing power and resources of the mobile terminal on which AR depends are much weaker than in other areas. Currently, AR is still dominated by visual SLAM, supplemented by other sensors, although this situation is changing. The following discussion is mainly limited to visual SLAM.
The standard visual SLAM problem can be described as: Drop you into an unfamiliar environment and you have to solve the problem of "Where am I?" The "I" here is basically equivalent to the camera or the eye (because the monocular, that is, the single camera, please think of yourself as one-eyed dragon), "in" is to be localized (that is, localization), "what" needs a piece that does not originally exist The map that you need to build (that is, mapping). You walk with one eye and understand the surrounding environment (building a map) while determining the position (positioning) on ​​the map. This is SLAM. In other words, in the process of walking, on the one hand, the places seen by the camera are linked together into a map, and on the other hand, the trajectory to be found is found on the map. Below we look at what technologies are generally required for this process.
The process of inversely calculating the three-dimensional environment from the image sequence, namely mapping, belongs to the category of three-dimensional reconstruction in computer vision. In SLAM, we want to reconstruct images from successively acquired image sequences. These image sequences are acquired during the camera's movement, so the related technique is called motion-based reconstruction (SfM). Digressively, SfX is a technique for visually referencing three-dimensional reconstructions from X. X can have something other than motion (such as Structure from Shading). What if the camera does not move? It's hard to do. How can one-eyed dragon stand around in the three-dimensional situation? In principle, once there is motion between the two images acquired, it means that two eyes can see the scene at the same time (note the pit, assuming the scene does not move), can it not be stereoscopic? In this way, multi-dimensional geometry comes in handy. Further, the actual motion we get is a series of images rather than just two. It is natural that we can use them together to optimize and improve the accuracy. This is the bundle adjustment that makes small white people unclear.
What about localization? If you have a map and you have a coordinate system, the positioning problem is basically the same as the aforementioned 2D tracking (of course it's more complicated). Let us consider the method based on the control point. Now we need to find and track the control point in the three-dimensional space to calculate. Coincidentally (really?), the above multi-view geometry also requires control points for 3D reconstructions, which are often shared. Can you use the direct method? Yes we can! However, as will be discussed later, due to the limited computing resources currently available in AR, the control point method is more economical.
From the methods and results of three-dimensional reconstruction, SLAM can be roughly classified into sparse, semi-dense and dense. A typical example is given in FIG.

Dense SLAM: In short, the purpose of Dense SLAM is to reconstruct all the information collected by the camera in three dimensions. In layman's terms, it is to calculate its position and distance to the camera for each point of space it sees, or to know its position in physical space. Among the AR-related work, DTAM and KinectFusion have recently become more influential. The former is purely visual, while the latter uses a depth camera. Because of the need to do azimuth calculations on almost all collected pixels, the computational complexity of dense SLAM is a lever, so it is not a civilian AR (such as a typical mobile phone, friends holding 6S/S7/Mate8 do not arrogant arrogance, these are all Count "general").
Sparse SLAM: The 3D output of sparse SLAM is a series of 3D point clouds. For example, the corners of a three-dimensional cube. Compared to a solid three-dimensional world (such as the face of a cube and the middle belly), the reconstruction of the three-dimensional environment provided by the point cloud is sparse. In practical applications, the required spatial structure (such as the desktop) is extracted or inferred based on these point clouds, and then the AR content rendering can be superimposed on these structures. Compared to the dense SLAM version, sparse SLAMs are concerned with the number of points lower than the full two dimensions (falling from the surface to the point), which naturally becomes the first choice for the civilian AR. The sparse SLAMs that are currently popular are mostly based on variants of the PTAM framework, such as the recent hot ORB-SLAM.
Semi-dense SLAM: As the name implies, the density of semi-dense SLAM is between the above two, but it is not strictly defined. The most recent representative of the semi-dense SLAM is the LSD-SLAM, but for the application in the AR, there is currently no sparse SLAM.
Due to the popularity of sparse SLAM in AR, we briefly introduce PTAM and ORB-SLAM. Prior to PTAM, the SLAM, proposed by A. Davison in 2003, pioneered the real-time monocular SLAM. The basic idea of ​​this work was based on the mainstream SLAM framework in the field of robotics at that time. Simply put, the process of "Track-Match-Map-Update" is performed for each new incoming image of each frame. However, the effectiveness and efficiency of this framework on the mobile end (mobile phone) are not satisfactory. For the SLAM requirements of the mobile AR, Klein and Murray demonstrated the stunning PTAM system in ISMAR (the flagship academic conference in the AR field) in 2007, thus becoming the most commonly used framework for Monocular Vision AR SLAM.
The full name of PTAM is Parallel Tracking And Mapping, which has been implied above. PTAM and previous SLAM are different in the framework. We know that SLAM performs two operations on each frame simultaneously: localization and mapping. Due to the huge resource consumption, these two types of operations are difficult to fully implement for each frame in real time. Then do we have to locate and build maps every frame at the same time? Look at the positioning first, this must be done every frame, otherwise we don't know where we are. So what about graphics? Fortunately, this does not need to be done every frame, because we can still perceive the scene through SfM several frames apart. Imagine throwing you in a strange scene, allowing you to explore the surroundings while walking, but only let you see 10 eyes per second, as long as you are not flying, I believe this task can still be completed. The core idea of ​​PTAM is here, not to be positioned and mapped graphically, but to separate them and run in parallel. The positioning here is based on frame-by-frame tracking, so there is tracking. The cartography is no longer carried out frame by frame, but depends on the computing power. When the current work is finished, it is time to take a new look. In this framework, with the control points selected matching and other optimization combinations, PTAM appeared on the audience with its gorgeous demo (this is almost 10 years ago).
The story clearly does not end in this way. We all know that there is a gap between demo and utility, not to mention demos in academia. However, under the guidance of the PTAM idea, researchers continuously improve and update. The best of them is the ORB-SLAM mentioned above. ORB-SLAM was published by IEEE-Transaction on Robotics in 2015 by Mur-Artal, Montiel and Tardos. Due to its excellent performance and intimate source code, ORB-SLAM quickly gained the favor of both industry and academia.ä¸è¿‡ï¼Œå¦‚果打算通读其论文的è¯ï¼Œè¯·å…ˆåšå¥½è¢«éƒé—·çš„心ç†å‡†å¤‡ã€‚ä¸æ˜¯å› 为有太多晦涩的数å¦å…¬å¼ï¼Œæ°æ°ç›¸åï¼Œæ˜¯å› ä¸ºåŸºæœ¬ä¸Šæ²¡æœ‰å•¥å…¬å¼ï¼Œè€Œæ˜¯å……满了让人ä¸æ˜Žè§‰åŽ‰çš„åè¯ã€‚ Why is this?其实和ORB-SLAMçš„æˆåŠŸæœ‰å¾ˆå¤§å…³ç³»ã€‚ ORB-SLAM虽然ä»ç„¶åŸºäºŽPTAM的基本框架,ä¸è¿‡ï¼Œåšäº†å¾ˆå¤šå¾ˆå¤šæ”¹è¿›ï¼ŒåŠ 了很多很多东西。从æŸä¸ªè§’度看,å¯ä»¥æŠŠå®ƒçœ‹ä½œä¸€ä¸ªé›†å¤§æˆçš„且精心优化过的系统。所以,区区17页的IEEEåŒæ 论文是ä¸å¯èƒ½ç»™å‡ºç»†èŠ‚的,细节都在å‚考文献里é¢ï¼Œæœ‰äº›ç”šè‡³åªåœ¨æºç 里。 在众多的改进ä¸ï¼Œæ¯”较大的包括控制点上使用更为有效的ORB控制点ã€å¼•å…¥ç¬¬ä¸‰ä¸ªçº¿ç¨‹åšå›žçŽ¯æ£€æµ‹çŸ«æ£ï¼ˆå¦å¤–两个分别是跟踪和制图)ã€ä½¿ç”¨å¯è§†æ ‘æ¥å®žçŽ°é«˜æ•ˆçš„多帧优化(还记得集æŸçº¦æŸå—)ã€æ›´ä¸ºåˆç†çš„关键帧管ç†ã€ç‰ç‰ã€‚
有朋å‹è¿™é‡Œä¼šæœ‰ä¸€ä¸ªç–‘问:既然ORB-SLAM是基于PTAM的框架,那为啥ä¸å«ORB-PTAM呢?是酱紫的:尽管从框架上看PTAMå·²ç»å’Œä¼ 统SLAM有所ä¸åŒï¼Œä½†æ˜¯å‡ºäºŽå„ç§åŽŸå› ,SLAM现在已ç»æ¼”å˜æˆä¸ºè¿™ä¸€ç±»æŠ€æœ¯çš„统称。也就是说,PTAM一般被认为是SLAMä¸çš„一个具体算法,确切些说是å•ç›®è§†è§‰SLAM的一个算法。所以呢,ORB-PTAMå°±å«ORB-SLAM了。
尽管近年æ¥çš„进展使得å•ç›®SLAMå·²ç»èƒ½åœ¨ä¸€äº›åœºæ™¯ä¸Šç»™å‡ºä¸é”™çš„结果,å•ç›®SLAM在一般的移动端还远远达ä¸åˆ°éšå¿ƒæ‰€æ¬²çš„效果。计算机视觉ä¸çš„å„ç§å‘还是ä¸åŒç¨‹åº¦çš„å˜åœ¨ã€‚在ARä¸æ¯”较刺眼的问题包括:
åˆå§‹åŒ–问题:å•ç›®è§†è§‰å¯¹äºŽä¸‰ç»´ç†è§£æœ‰ç€ä¸Žç”Ÿä¿±æ¥çš„æ§ä¹‰ã€‚尽管å¯ä»¥é€šè¿‡è¿åŠ¨æ¥èŽ·å¾—æœ‰è§†å·®çš„å‡ å¸§ï¼Œä½†è¿™å‡ å¸§çš„è´¨é‡å¹¶æ²¡æœ‰ä¿è¯ã€‚æžç«¯æƒ…况下,如果用户拿ç€æ‰‹æœºæ²¡åŠ¨ï¼Œæˆ–者åªæœ‰è½¬åŠ¨ï¼Œç®—法基本上就挂掉了。
快速è¿åŠ¨ï¼šç›¸æœºå¿«é€Ÿè¿åŠ¨é€šå¸¸ä¼šå¸¦æ¥ä¸¤æ–¹é¢çš„æŒ‘æˆ˜ã€‚ä¸€æ˜¯é€ æˆå›¾åƒçš„模糊,从而控制点难以准确获å–,很多时候就是人眼也很难判æ–。二是相邻帧匹é…区域å‡å°ï¼Œç”šè‡³åœ¨æžç«¯æƒ…况下没有共åŒåŒºåŸŸï¼Œå¯¹äºŽå»ºç«‹åœ¨ç«‹ä½“匹é…ä¹‹ä¸Šçš„ç®—æ³•é€ æˆå¾ˆå¤§çš„困扰。
纯旋转è¿åŠ¨ï¼šå½“相机åšçº¯æ—‹è½¬æˆ–近似纯旋转è¿åŠ¨æ—¶ï¼Œç«‹ä½“è§†è§‰æ— æ³•é€šè¿‡ä¸‰è§’åŒ–æ¥ç¡®å®šæŽ§åˆ¶ç‚¹çš„空间ä½ç½®ï¼Œä»Žè€Œæ— 法有效地进行三维é‡å»ºã€‚
动æ€åœºæ™¯ï¼š SLAM通常å‡è®¾åœºæ™¯åŸºæœ¬ä¸Šæ˜¯é™æ¢çš„。但是当场景内有è¿åŠ¨ç‰©ä½“的时候,算法的稳定性很å¯èƒ½ä¼šå—到ä¸åŒç¨‹åº¦çš„干扰。
对AR行业动æ€æœ‰äº†è§£çš„朋å‹å¯èƒ½ä¼šæœ‰äº›ç–‘惑,上é¢è¯´å¾—这么难,å¯æ˜¯HoloLens一类的东西好åƒæ•ˆæžœè¿˜ä¸é”™å“¦ï¼Ÿæ²¡é”™ï¼Œä¸è¿‡æˆ‘们上é¢è¯´çš„是å•ç›®æ— ä¼ æ„Ÿå™¨çš„æƒ…å†µã€‚ä¸€ä¸ªHoloLenså¯ä»¥ä¹°äº”个iPhone 6S+ï¼Œé‚£ä¹ˆå¤šä¼ æ„Ÿå™¨ä¸æ˜¯å…费的。ä¸è¿‡è¯è¯´å›žæ¥ï¼Œåˆ©ç”¨é«˜è´¨é‡ä¼ 感器æ¥æ高精度必然是AR SLAMçš„é‡è¦è¶‹åŠ¿ï¼Œä¸è¿‡ç”±äºŽæˆæœ¬çš„é—®é¢˜ï¼Œè¿™æ ·çš„ARå¯èƒ½è¿˜éœ€è¦ä¸€å®šæ—¶é—´æ‰èƒ½ä»Žé«˜ç«¯å±•ä¼šèµ°åˆ°æ™®é€šç”¨æˆ·ä¸ã€‚
4ã€SMART: è¯ä¹‰é©±åŠ¨çš„多模æ€å¢žå¼ºçŽ°å®žå’Œæ™ºèƒ½äº¤äº’å•ç›®AR(å³åŸºäºŽå•æ‘„åƒå¤´çš„AR)虽然有ç€å¾ˆå¤§çš„市场(想想数亿的手机用户å§ï¼‰ï¼Œä½†æ˜¯å¦‚上文所忧,ä»ç„¶éœ€è¦è§£å†³å¾ˆå¤šçš„技术难题,有一些甚至是超越å•ç›®AR的能力的。任何一个有ç†æƒ³æœ‰è¿½æ±‚有情怀的ARå…¬å¸ï¼Œæ˜¯ä¸ä¼šä¹Ÿä¸èƒ½å±€é™äºŽä¼ 统的å•ç›®æ¡†æž¶ä¸Šçš„。那么除了å•ç›®ARå·²ç»å»ºç«‹çš„技术基础外,ARçš„å‰æ²¿ä¸Šæœ‰å“ªäº›é‡è¦çš„阵地呢?纵观AR和相关软硬件方å‘çš„å‘展历å²å’Œäº‹æ€ï¼Œæ¨ªçœ‹ä»Šå¤©å„è·¯ARè¯¸ä¾¯çš„æŠ€æœ¯é£Žæ ‡ï¼Œ ä¸éš¾æ€»ç»“出三个主è¦çš„æ–¹å‘:è¯ä¹‰é©±åŠ¨ï¼Œå¤šæ¨¡æ€èžåˆï¼Œä»¥åŠæ™ºèƒ½äº¤äº’。éµå¾ªä¸šç•Œæ€§æ„Ÿé€ è¯çš„惯例,我们将他们总结æˆï¼š
SMART:Semantic Multi-model AR inTeraction
å³â€œè¯ä¹‰é©±åŠ¨çš„多模æ€å¢žå¼ºçŽ°å®žå’Œæ™ºèƒ½äº¤äº’â€ã€‚由于这三个方é¢éƒ½è¿˜åœ¨é£žé€Ÿå‘展,技术日新月异,我下é¢å°±å‹‰å¼ºåœ°åšä¸€ä¸ªç²—浅的介ç»ï¼Œè¡¨æ„为主,请勿钻牛角尖。
è¯ä¹‰é©±åŠ¨ï¼šè¯ä¹‰é©±åŠ¨åœ¨ä¼ ç»Ÿçš„å‡ ä½•ä¸ºä¸»å¯¼çš„ARä¸å¼•å…¥è¯ä¹‰çš„æ¦‚å¿µï¼Œå…¶æŠ€æœ¯æ ¸å¿ƒæ¥æºäºŽå¯¹åœºæ™¯çš„è¯ä¹‰ç†è§£ã€‚为什么è¦è¯ä¹‰ä¿¡æ¯ï¼Ÿç”案很简å•ï¼Œå› 为我们人类所ç†è§£çš„世界是充满è¯ä¹‰çš„。如图11所列,我们所处的物ç†ä¸–ç•Œä¸ä»…是由å„ç§ä¸‰ç»´ç»“构组æˆçš„,更是由诸如é€æ˜Žçš„窗ã€ç –é¢çš„墙ã€æ”¾ç€æ–°é—»çš„电视ç‰ç‰ç»„æˆçš„。对于ARæ¥è¯´ï¼Œåªæœ‰å‡ 何信æ¯çš„è¯ï¼Œæˆ‘们å¯ä»¥â€œæŠŠè™šæ‹Ÿèœå•å åŠ åˆ°å¹³é¢ä¸Šâ€ï¼›æœ‰äº†è¯ä¹‰ç†è§£åŽï¼Œæˆ‘们就å¯ä»¥â€œæŠŠè™šæ‹Ÿèœå•å åŠ åˆ°çª—æˆ·ä¸Šâ€ï¼Œæˆ–者邪æ¶åœ°â€œæ ¹æ®æ£åœ¨æ’放的电视节目显示相关广告â€ã€‚
ç›¸æ¯”å‡ ä½•ç†è§£ï¼Œå¯¹äºŽè§†è§‰ä¿¡æ¯çš„è¯ä¹‰ç†è§£æ¶µç›–å¹¿å¾—å¤šçš„å†…å®¹ï¼Œå› è€Œä¹Ÿæœ‰ç€å¹¿å¾—å¤šçš„åº”ç”¨ã€‚å¹¿ä¹‰çš„çœ‹ï¼Œå‡ ä½•ç†è§£ä¹Ÿå¯ä»¥çœ‹ä½œæ˜¯è¯ä¹‰ç†è§£çš„一个å集,å³å‡ ä½•å±žæ€§æˆ–å‡ ä½•è¯ä¹‰ã€‚那么,既然è¯ä¹‰ç†è§£è¿™ä¹ˆå¥½è¿™ä¹ˆå¼ºå¤§ï¼Œä¸ºå•¥æˆ‘们今天æ‰å¼ºè°ƒå®ƒï¼Ÿéš¾é“先贤们都没有我们èªæ˜Žï¼Ÿå½“然ä¸æ˜¯ï¼Œåªæ˜¯å› 为è¯ä¹‰ç†è§£å¤ªéš¾äº†ï¼Œä¹Ÿå°±æœ€è¿‘的进展æ‰ä½¿å®ƒæœ‰å¹¿æ³›å®žç”¨çš„å¯èƒ½æ€§ã€‚当然,通用的对任æ„场景的完全è¯ä¹‰ç†è§£ç›®å‰è¿˜æ˜¯ä¸ªéš¾é¢˜ï¼Œä½†æ˜¯å¯¹äºŽä¸€äº›ç‰¹å®šç‰©ä½“çš„è¯ä¹‰ç†è§£å·²ç»åœ¨ARä¸æœ‰äº†å¯è¡Œçš„应用,比如AR辅助驾驶和AR人脸特效(图12)。

多模æ€èžåˆï¼šéšç€å¤§å¤§å°å°çš„AR厂家陆ç»æŽ¨å‡ºå½¢å½¢è‰²è‰²çš„AR硬件,多模æ€å·²ç»æ˜¯ARä¸“ç”¨ç¡¬ä»¶çš„æ ‡é…,åŒç›®ã€æ·±åº¦ã€æƒ¯å¯¼ã€è¯éŸ³ç‰ç‰åè¯çº·çº·å‡ºçŽ°åœ¨å„ä¸ªç¡¬ä»¶çš„æŠ€æœ¯æŒ‡æ ‡æ¸…å•ä¸ã€‚这些硬件的å¯ç”¨æ˜¾ç„¶æœ‰ç€å…¶èƒŒåŽçš„算法用心,å³åˆ©ç”¨å¤šæ¨¡æ€çš„ä¿¡æ¯æ¥æ高ARä¸çš„对环境和交互的感知ç†è§£ã€‚比如,之å‰åå¤æ到,作为ARæ ¸å¿ƒçš„çŽ¯å¢ƒè·Ÿè¸ªç†è§£é¢ä¸´ç€äº”花八门的技术挑战,有些甚至çªç ´äº†è§†è§‰ç®—法的界é™ï¼Œè¿™ç§æƒ…况下,éžè§†è§‰çš„ä¿¡æ¯å°±å¯ä»¥èµ·åˆ°é‡è¦çš„补充支æŒä½œç”¨ã€‚比如说,在相机快速è¿åŠ¨çš„情况下,图åƒç”±äºŽå‰§çƒˆæ¨¡ç³Šè€Œä¸§å¤±ç²¾å‡†æ€§ï¼Œä½†æ¤æ—¶çš„姿æ€ä¼ 感器给出的信æ¯è¿˜æ˜¯æ¯”较å¯é 的,å¯ä»¥ç”¨æ¥å¸®åŠ©è§†è§‰è·Ÿè¸ªç®—法度过难关。
智能交互: 从æŸä¸ªè§’度æ¥çœ‹ï¼Œäººæœºäº¤äº’çš„å‘展å²å¯ä»¥çœ‹ä½œæ˜¯è¿½æ±‚自然交互的历å²ã€‚从最早的纸带打å”到如今窗å£å’Œè§¦å±äº¤äº’,计算机系统对使用者的专业è¦æ±‚越æ¥è¶Šä½Žã€‚è¿‘æ¥ï¼Œæœºå™¨æ™ºèƒ½çš„å‘展使得计算机对人类的自然æ„识的ç†è§£è¶Šæ¥è¶Šå¯é ,从而使智能交互有了从实验室走å‘实用的契机。从视觉åŠç›¸å…³ä¿¡æ¯æ¥å®žæ—¶ç†è§£äººç±»çš„交互æ„图æˆä¸ºAR系统ä¸çš„é‡è¦ä¸€çŽ¯ã€‚在å„ç§è‡ªç„¶äº¤äº’ä¸ï¼ŒåŸºäºŽæ‰‹åŠ¿çš„技术是目å‰ARçš„çƒç‚¹ã€‚一方é¢ç”±äºŽæ‰‹åŠ¿çš„技术比较æˆç†Ÿï¼Œå¦ä¸€æ–¹é¢ä¹Ÿç”±äºŽæ‰‹åŠ¿æœ‰å¾ˆå¼ºçš„å¯å®šåˆ¶æ€§ã€‚关于手势需è¦ç§‘普的一个地方是:手势估计和手势识别是两个紧密相关但ä¸åŒçš„概念。手势估计是指从图åƒï¼ˆæˆ–者深度)数æ®ä¸å¾—到手的精确姿势数æ®ï¼Œæ¯”如所有手指关节的3Dåæ ‡ï¼ˆå›¾13);而手势识别是指判æ–出手的动作(或姿æ€ï¼‰è¯´ä»£è¡¨çš„è¯ä¹‰ä¿¡æ¯ï¼Œæ¯”如“打开电视â€è¿™æ ·çš„命令。å‰è€…一般å¯ä»¥ä½œä¸ºåŽè€…的输入,但是如果手势指令集ä¸å¤§çš„情况下,也å¯ä»¥ç›´æŽ¥åšæ‰‹åŠ¿è¯†åˆ«ã€‚å‰è€…的更准确å«æ³•åº”该是手的姿势估计。

增强现实的å†åº¦å…´èµ·æ˜¯ç”±è¿‘å¹´æ¥è½¯ç¡¬ä»¶çš„进展决定的,是科å¦å’ŒæŠ€æœ¯äººå‘˜å‡ å年努力的推动æˆæžœã€‚一方é¢ï¼Œå¾ˆå¹¸è¿æˆ‘们能够赶上这个时代æ供的机会;å¦ä¸€æ–¹é¢ï¼Œæˆ‘们也应该è¦æƒ•è¿‡åº¦çš„ä¹è§‚,需è¦è„šè¸å®žåœ°å¾—趟过æ¯ä¸€ä¸ªå‘。
SnowWolf Lucky Wolf Legend 25K Disposable Vape
SnowWolf Lucky Wolf Legend 25K Disposable Vape is the innovative vape powered by SnowWolf. With a large reservoir for vape juice, Luck Wolf can offer around 25000 puffs. The large HD screen is another outstanding feature of SnowWolf Legend 25K. It shows battery status, e-juice level, and the current vaping mode you choose with clear numbers and animation. User-friendliness is the priority. Lucky Wolf Legend has only one button for operation. Press it for 4 seconds to turn it on or off. The Stealth Mode can be activated with double clicks.
SnowWolf 25K Disposable Vape, Yingyuan Vape,Ecig
Shenzhen Yingyuan Technology Co.,ltd , https://www.smartpuffvape.com