
Introduce a multiplication and division algorithm that saves time and saves resources
At present, the market competition of the single-chip microcomputer is very fierce, and many applications use the 8-bit MCU chip of small resources (such as 1K and 2K) with small program storage space for development. Under normal circumstances, this kind of MCU does not have hardware multiplication or division instructions. When the program must use multiplication and division, if you simply rely on the compiler to call the internal function library to achieve, there are often the disadvantages of large code size and low execution efficiency.
Shanghai MCC MC30 and MC32 series MCUs have adopted the RISC architecture and have a large user base and wide application in the 8-bit MCU field of small resources. This article will use the instructions of these two series of products. Set as an example, combined with the compilation and C compiler platform, to introduce a time-saving and resource-saving multiplication and division algorithm.
Multiplication
The multiplication in the MCU is a binary multiplication, that is to multiply the bits of the multiplier with the multiplicand, and then add them, because the multiplier and the multiplicand are both binary, so the multiplication of each step in the actual programming Can use shift to achieve.
For example: multiplier R3=01101101, multiplicand R4=11000101, product R1R0. Proceed as follows
1, empty product R1R0;
2. The 0th bit of the multiplier is 1, and the multiplicand R4 needs to be multiplied by the binary number 1, that is, 0 bits to the left and added to R1R0;
3, the first bit of the multiplier is 0, ignored;
4, the second bit of the multiplier is 1, that is, the multiplier R4 needs to multiply the binary number 100, that is, 2 bits to the left, added to R1R0;
5, the third digit of the multiplier is 1, the multiplier R4 needs to multiply the binary number 1000, that is, left shift 3, added to R1R0;
6, the 4th bit of the multiplier is 0, ignored;
7. The 5th bit of the multiplier is 1, and the multiplicand R4 needs to multiply the binary number 100000, that is, 5 bits to the left, and add it to R1R0;
8, the 6th bit of the multiplier is 1, that is, the multiplier R4 needs to multiply the binary number 1000000, that is, left shift 6 bits, added to R1R0;
9, the 7th bit of the multiplier is 0, ignored;
10. At this time, the value in R1R0 is the final product. At this point, the algorithm is completed.
The above example operation result:
R1R0 = R3 * R4 = (R4<<6)+(R4<<5)+(R4<<3)+(R4<<2)+R4 = 101001111100001
The actual operation flow chart is shown in Figure 1.1.
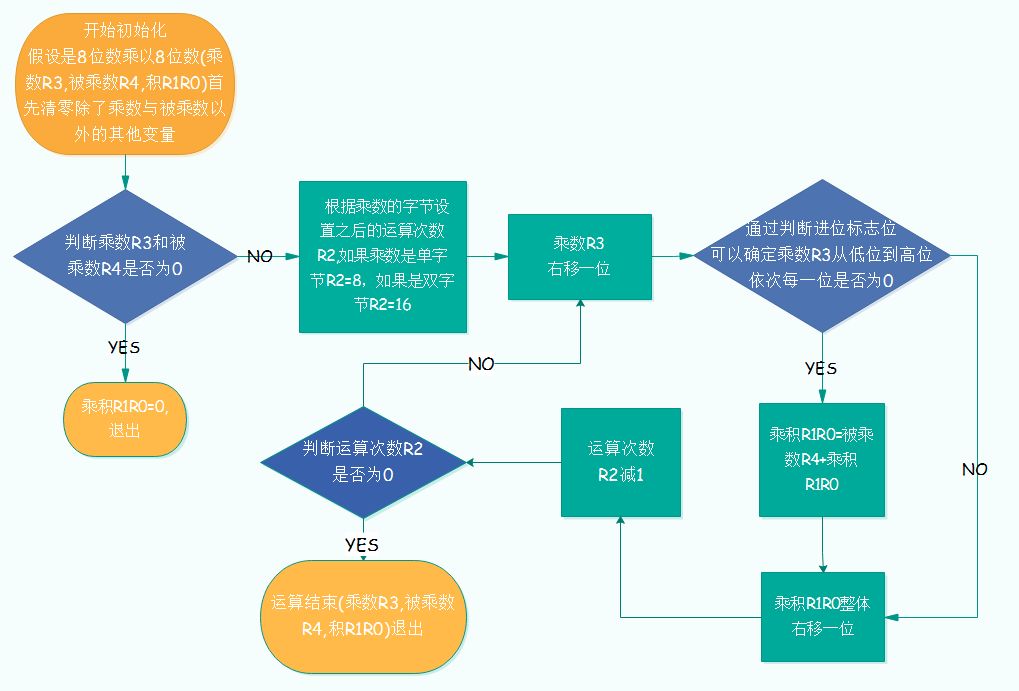
Figure 1.1 Compilation Multiplication Flow
In the actual program design process, program optimization has two goals, improve program operation efficiency, and reduce the amount of code. Let's take a look at the comparability of the assembler algorithm provided by this article and the efficiency and code size of ordinary C programming.
Table 1.1 is the comparison data of the operating efficiency of the program (there may be small deviations). Obviously, the assembly and compilation run time is much less than the C language.
| Assembly (clock cycle) | C language (clock cycle) | |
| 8*8 bit multiplication | 79-87 | 184-190 |
| 16*8 bit multiplication | 201-210 | 362-388 |
| 16*16-bit multiplication | 234-379 | 396-468 |
Table 1.1 Multiplication clock cycle comparison table
Table 1.2 is the comparison data of the program code (there may be small deviations), and the program space occupied by the assembly is also much smaller than that of the C language.
| Assembly (Byte) | C language (Byte) | |
| 8*8 bit multiplication | 15 | 34 |
| 16*8 bit multiplication | 19 | 96 |
| 16*16-bit multiplication | 31 | 96 |
Table 1.2 Multiplication ROM Space Usage Comparison Table
To sum up two points, the multiplication algorithm used in this article will be much better than the C compiler. If everyone is in the process of using, the original program can not meet the application requirements, for example, the problems such as insufficient program space or long running time can be optimized according to the above methods. Assembly language is closest to the machine language. Registers can be manipulated directly in assembly language to adjust the instruction execution sequence. As the assembly language directly faces the hardware platform, the instruction set and instruction cycle of different hardware platforms are quite different. This will cause some inconvenience to the transplantation and maintenance of the program, so we have done a multiplication operation for the lean instruction set. Routines are easy to transplant and understand.




Division
The division in the single-chip microcomputer is also the division of binary, similar to the division of the mathematics in the real world, starting from the high position of the dividend, performing the operation of taking the remainder of the divisor by the bit, and the resulting remainder is then subjected to a new phase together with the subsequent dividend. In addition to retrieving the remainder of the operation, it is not until inexhaustible, because the division in the MCU is binary, and the quotient out of each step is only 1 at most, so we can regard the division of each step as the subtraction in the actual programming.
For example, dividend R3R4=1100110001101101, divisor R5=11000101, quotient R1R0, remainder R2. Proceed as follows
1. Clear quotient R1R0, remainder R2;
2. The dividend is released by the highest position, and the 15th bit is 1, 1 is smaller than the divisor, the quotient is 0, and the remainder R2 is 1;
3. The remainder of the previous step is divided by several highs. At the 14th position, the 11,11 is still smaller than the divisor, the quotient is 0, and the remainder R2 is 11
4, until the release of the eighth place, get 11001100, more than the divisor, get 1 and the remainder R2 is 111;
5. The remainder of the previous step is divided by the 7th bit of the dividend to get 1110. There is no divisor, the quotient is 0, and the remainder R2 is 1110;
6. The remainder of the previous step is divided by the 6th digit to get 11101. There is no divisor, the quotient is 0, and the remainder R2 is 11101;
7, in accordance with the above steps, until you release the third digit of the dividend, to 11101101, greater than the divisor, the quotient is 1, the remainder R2 is 101000;
8, the remainder of the previous step is divided by the second bit, to 1010001, no divisor is large, the quotient is 0, the remainder R2 is 1010001;
9. The remainder of the previous step is divided by the first digit to get 10100010. There is no divisor, the quotient is 0, and the remainder R2 is 10100010;
10. The remainder of the previous step is divided by the 0th bit of the dividend, which is 101000101. It is larger than the divisor, the quotient is 1, and the remainder R2 is 10000000;
11, then all the above steps in the order of business from left to right is the last business 100001001, the remainder is the final calculation of the remainder of 10000000.
The above example operation result R1R0 = R3R4 / R5 = 100001001
R2 = R3R4 % R5 = 10000000
The actual operation flow chart is shown in Figure 2.1.
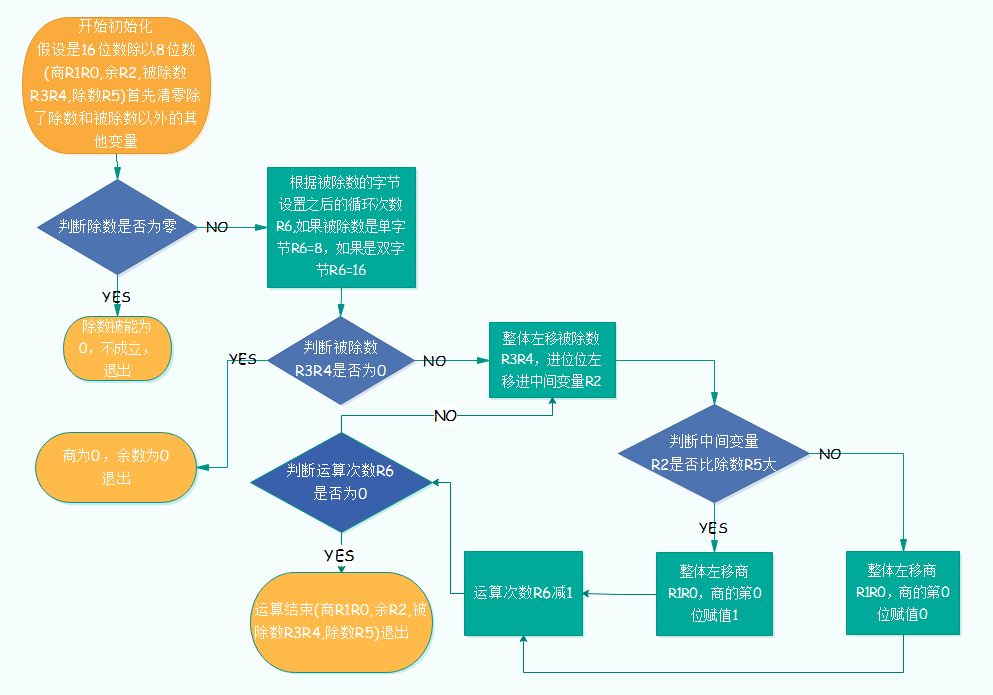
Figure 2.1 Compilation and division flow chart
The efficiency of the division, the amount of code in the following table
Table 1.1 is the comparison data of program operation efficiency and code size (there may be small deviations). Obviously, the compilation algorithm provided in this paper is to be optimized.
| 16/8 bit division | compilation | C language |
| Clock cycle | 287-321 | 740-804 |
| Using Byte | 35 | 142 |
Table 2.1 Comparison of clock cycles for division
So for the division operation, the method provided in this paper is also relatively superior.
The following are the 16/8-bit routines for the division of the reduced instruction set, which is convenient for everyone's transplantation and understanding.


DMX Controller
MA Black Horse DMX Controller lighting console
Technical Parameter
1.Intel core 3 generation processor Inter(R) core (TM) i5-3380M CPU
2. 120 GB solid state disk, 8 GB memory, corn I5 motherboard
3.standard 6 DMX output ports and MIDI interfaces, 3072 DMX channels
4. Built-in two 19-inch high-definition touch screens
5.21 program playback putter, 42 program storage function keys
6. 1 main control dimming wheel, 4 attribute coding wheel
7. 1 mian control putter, 2 AB putter
8 Hydraulic screen Angle adjustment support structure
9.size: 82*680*130mm, G, weight: about 56KG with flycase
Our company have 13 years experience of LED Display and Stage Lights , our company mainly produce Indoor Rental LED Display, Outdoor Rental LED Display, Transparent LED Display,Indoor Fixed Indoor LED Display, Outdoor Fixed LED Display, Poster LED Display , Dance LED Display ... In additional, we also produce stage lights, such as beam lights Series, moving head lights Series, LED Par Light Series and
Controller Series,DMX Controller,Console,DMX Console
Guangzhou Chengwen Photoelectric Technology co.,ltd , https://www.cwstagelight.com