
Detailed definition and usage of Awk in Linux
Awk, sed and grep, commonly known as the three Musketeers under Linux, they have many similarities before, but they also have their own characteristics. The similarity is that they can match text, and sed and awk can also be used for text editing. Grep does not have this function. Sed is a non-interactive stream-oriented editor, and awk is a pattern-matching programming language because its main function is to match text and Processing, at the same time it has some programming language grammar, such as functions, branch loop statements, variables, etc. Of course, Awk is relatively simple compared to our common programming language.
With Awk, we can do the following:
Treat a text file as a text database consisting of fields and records;
Variables can be used in the process of manipulating a text database;
Ability to use mathematical operations and string operations;
Ability to use common programming structures such as conditional branches and loops;
Ability to format output;
Ability to customize functions;
Ability to execute UNIX commands in awk scripts;
Ability to handle the output of UNIX commands;
With the above functions, awk can do a lot of things. But the journey of a thousand miles begins with a single step. We start with the most basic command line grammar and step by step into the awk programming world.
Command line syntax
Like sed, awk's command line syntax has two forms:

The program here is similar to the script in sed, because we have always emphasized that awk is a programming language, so the awk script is treated as a piece of code. The awk script can also be written to a file and specified with the -f parameter, which is the same as sed. The program generally consists of multiple patterns and action sequences. When the read record matches the pattern, the corresponding action command is executed. One thing to note here is that in the first form, except for the command line options, the program parameter must be in the first position.
Awk's input is parsed into multiple records. By default, the record's separator is, so you can think of a line as a record, and the record's separator can be changed by the built-in variable RS. Subsequent action commands are executed when the record matches a pattern.
Each record is further divided into multiple fields. By default, the field separator is a white space, such as a space, a tab, etc. It can also be changed with the -F ERE option or the built-in variable FS. In awk, you can access the corresponding position field through $1, $2..., and $0 stores the entire record, which is somewhat similar to the command line position parameter in the shell. We will elaborate on these contents below. You only need to know that there are these things.
The standard awk command line parameters are mainly composed of the following three:
-F ERE: defines the field separator, the value of this option can be an extended regular expression (ERE);
-f progfile: Specify awk script, you can specify multiple scripts at the same time, they will be connected in the order they appear in the command line;
-v assignment: defines the awk variable, the form is the same as the variable assignment in awk, ie name=value, the assignment occurs before awk processes the text;
For ease of understanding, here are a few simple examples. Set the colon with the -F parameter: as a separator and print each field:

Access the variables set with the -v option in the awk script:

As you can see from the above, the variable set with the -v option is accessible at the BEGIN location. BEGIN is a special pattern that is executed before awk processes the input. It can be thought of as an initialization statement, and END is also associated with this.
It seems that I have not introduced how to specify the file to be processed. Is the final argument the specified file? Before I read this book, I thought so, but in fact arraymnt has two forms, they are input file (file) and variable assignment (signal).
Awk can specify multiple input files at the same time. If the file name of the input file is '-', it means reading content from standard input.
Variable assignments are similar to the -v option, which takes the form name=value. The variable name in awk is not much different from the general programming language, but it cannot be the same as the awk reserved keyword. You can check the awk man page to find out which keywords are reserved. Variable values ​​come in only two forms: strings and values. The variable assignment must be located after the script parameter, and there is no order requirement with the file name parameter, but the execution timing of the assignment at a different location is different.
We use a practical example to explain this difference, assuming two files: a and b, whose contents are as follows:

To illustrate the timing of the assignment, we print the value of the variable in three places: BEGIN, normal processing, and END.
The first case: variable assignment is before all file name parameters

Result: The assignment operation occurs before normal processing, after the BEGIN action.
The second case: the variable assignment is after all file names:

Result: The assignment operation occurs after normal processing, before the END action.
The third case: variable assignment is between file names:

Result: The assignment operation occurs after the previous file is processed and is located before the file after processing;
Summarized as follows:
If the variable assignment is before the first file parameter, it is executed after the BEGIN action, affecting normal processing and END actions;
If the variable assignment is executed after the last file parameter and before the END action, only the END action is affected;
If the file parameter does not exist, the situation is the same as 1;
If the variable assignment is between multiple file parameters, the file before the variable assignment is processed and executed, affecting the processing of subsequent files and the END action;
Therefore, variable assignment must be considered for clear use, otherwise it is easier to make mistakes, but in general, variable assignment will not be used.
Naturally everyone will compare the variable assignment with the -v assignment option, the assignment is consistent, but the execution time of the -v option is earlier than the variable assignment:

It can be seen that the assignment of the -v option is performed before the BEGIN action.
Variable assignment must be careful not to duplicate the reserved keyword, otherwise it will report an error:

Record and Field
For a database, a database table is composed of multiple records, each row representing a record (Record). Each record consists of multiple columns, each column representing a field. Awk treats a text file as a text database, so it also has the concept of records and fields. By default, the separator of the record is carriage return, and the separator of the field is a white space, so each line of the text file represents a record, and the content of each line is separated into multiple fields by white space. With fields and records, awk has the flexibility to handle the contents of a file.
The default field separator can be modified with the -F option. For example, each line of /etc/passwd is separated by a colon into multiple fields, so you need to set the separator to a colon:
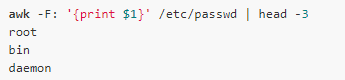
Here the first person field is referenced by $1, similarly $2 represents the second field, and $3 represents the third field.... $0 represents the entire record. The built-in variable NF records the number of fields, so $NF represents the last field:
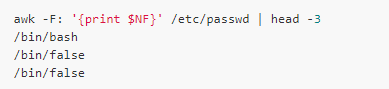
Of course, $(NF-1) means the second to last.
The built-in variable FS can also be used to change the field separator, which records the current field separator:
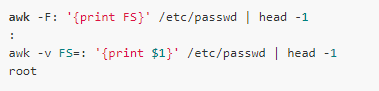
The separator of the record can be changed by the built-in variable RS:

If you set RS to null, the behavior is a bit weird. It treats all rows (one paragraph) that are not blank lines as one record, and forces carriage returns to be field separators:
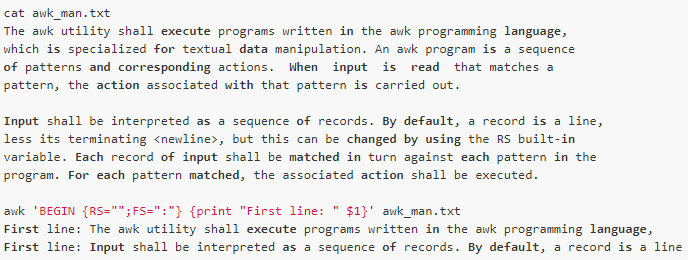
Here, we put the variable assignment into the BEGIN action, because the BEGIN action is executed before the file is processed, specifically for the initialization statement. The assignment of FS is invalid here, and awk still uses carriage returns to separate fields.
Script composition
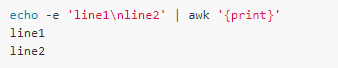
The program part of the command line can be called awk code, also known as awk script. An awk script consists of multiple 'pattern { action }' sequences. Action is one or more statements that are executed when the input line matches pattern. If pattern is empty, this action will be executed every line of processing. The following example simply prints each line of the file, where the print statement without any parameters prints the entire record, like 'print $0':
In addition to the pattern { action }, you can also define a custom function in the script. The function definition format is as follows:

The parameter list of the function is separated by commas. The parameter defaults to a local variable and cannot be accessed outside the function. The variable defined in the function is a global variable and can be accessed outside the function, such as:

Statements in Awk scripts are separated by blank lines or semicolons, and semicolons can be placed on the same line, but sometimes they can affect readability, especially in branch or loop structures, which can be error-prone.
If a statement in Awk is too long, to split into multiple lines, you can use the backslash '' in the behavior:

| Here we write the script to the file and specify it with the -f parameter. However, after some special symbols, you can wrap directly, for example, ", & { && | ". |
Pattern
The pattern is a more important part of awk, it has the following situations:
/regular expression/: Extended Regular Expression, for ERE can refer to this article;
Relational expression: A relational expression, such as greater than, less than, equal to, and the result of a relational expression is true to indicate a match;
BEGIN: A special mode that is executed before the first record processing, and is often used to initialize the execution of statements;
END: Special mode, which is executed before the last record processing, and is often used to output summary information;
Pattern, pattern: pattern pair, matching all records between the two, similar to the address pair of sed;
For example, look for a line that matches the number 3:
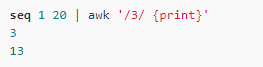
Conversely, you can add a '!' before the regular expression to indicate a mismatch:
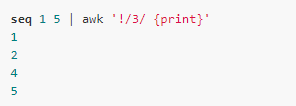
| In addition to the special modes BEGIN and END, the rest of the modes can use '&&' or ' | ' Operator combination, the former represents logical AND, and the latter represents logical or: |
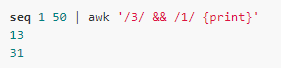
The previous rule is a whole line match, sometimes just need to match a character, so we can use the expression $n ~ /ere/:

Sometimes we just want to display specific lines and lines, for example to display the first line:
Regular Expression
The content of regular expressions is too cumbersome to introduce, and it is recommended that students read existing articles (such as the POSIX specification for Linux/Unix tools and regular expressions), which summarizes the regular expressions of each genre.
Expressions
Expressions can consist of constants, variables, operators, and functions. The values ​​of constants and variables can be strings and values.
There are three types of variables in Awk: user-defined variables, built-in variables, and field variables. Among them, the built-in variable names are all uppercase. Variables do not have to be declared or initialized. The value of an uninitialized string variable is "", and the value of an uninitialized numeric variable is 0. Field variables can be referenced with $n, where n has a range of [0, NF]. n can be a variable, such as the last field of the $NF code, and $(NF-1) represents the second to last field.
Array
An array is a special kind of variable. In awk, the index of an array can be a number or a string. The assignment of an array is very simple. The following assigns value to the element whose index is indexed as array: array[index]=value
You can traverse array elements with the for..in.. syntax, where item is the subscript corresponding to the array element: for (item in array)
Of course, you can also use the in operator in the if branch judgment: if (item in array)
A complete example is as follows:

Built-in variable
Awk internally maintains many built-in variables, or system variables, such as FS, RS, and so on. Common built-in variables are shown in the following table
| ARGC | The length of the command line arguments, ie the length of the ARGV array |
| ARGV | Store command line arguments |
| CONVFMT | Defines the format in which awk internal values ​​are converted to strings. The default value is "%.6g" |
| OFMT | Defines the format of the value converted to a string when outputting. The default value is "%.6g" |
| ENVIRON | Storing an associative array of system environment variables |
| FILENAME | The file name currently being processed |
| NR | Total number of records |
| FNR | The total number of records in the current file |
| FS | Field separator, default is blank |
| NF | The number of fields in each record |
| RS | Record separator, default is carriage return |
| OFS | The separator of the output field, the default is blank |
| ORS | The separator recorded when output, the default is carriage return |
| RLENGTH | The length of the substring matched by the match function |
| RSTART | The substring matched by the match function is located at the start of the target string. |
The following mainly introduces several built-in variables that are difficult to understand:
ARGV and ARGC
The meaning of ARGV and ARGC is better understood, just like the C language main(int argc, char **argv). The subscript of the ARGV array starts at 0 to ARGC-1, which stores command line arguments and excludes command line options (such as -v/-f) and program sections. So in fact ARGV is only the part that stores the argument, that is, the file name (file) and the contents of the command line variable assignment.
The following examples can give an overview of the usage of ARGC and ARGV:

The use of ARGV is not limited to this, it can be modified, you can change the value of array elements, you can add array elements or delete array elements.
Change the value of the ARGV element
Suppose we have two files, a and b, each with a line: file a and file b. Now with ARGV, we can do it by stealing the column:

It should be noted here that the quotation mark of ARGV[1]=â€b†cannot be absent, otherwise ARGV[1]=b will assign the value of variable b to ARGV[1].
When awk processes a file, it takes the parameters from the next element of ARGV. If it is a file, it continues processing. If it is a variable assignment, it performs the assignment:

When the next element is empty, skip the no processing, which avoids processing a file:

In the above example, the file a is skipped.
When the value of the next element is "-", it means reading from standard input:

Remove ARGV elements
The effect of deleting an ARGV element and assigning the value of the element to null is the same, and they all jump to the processing of a parameter:

To delete an array element, use the delete statement.
Increase ARGV elements
The first time I saw the ARGV variable, I was wondering if I could use the ARGV variable to avoid providing command line arguments, like this: awk 'BEGIN{ARGV[1]="a";} {print}'
But in fact this is not the case, awk will still get content from standard input. The following method is OK, first increase the value of ARGC, then increase the ARGV element, I have not understood the difference between the two:

CONVFMT and OFMT
Awk allows numeric to string conversion. The built-in variable CONVFMT defines the format of awk internal value to string conversion. Its default value is "%.6g":

By changing CONVFMT, we can define our own conversion format:

Correspondingly, there is a built-in variable OFMT, which is similar to CONVFMT, but is a format that converts numbers into strings when affecting output:

ENVIRON
ENVIRON is an associative array of system environment variables. Its subscript is the name of the environment variable, and the value is the value of the corresponding environment variable. E.g:

You can also pass values ​​to awk using environment variables:

You can use the for..in loop to traverse the ENVIRON array:

RLENGTH and RSTART
Both RLENGTH and RSTART are related to the match function. The former indicates the length of the matched substring, and the latter indicates that the matched substring is at the beginning of the target string. E.g:

Operator
The operators must be indispensable in the expression. The operators supported by awk can be found in the "Expressions in awk" section of the man page:
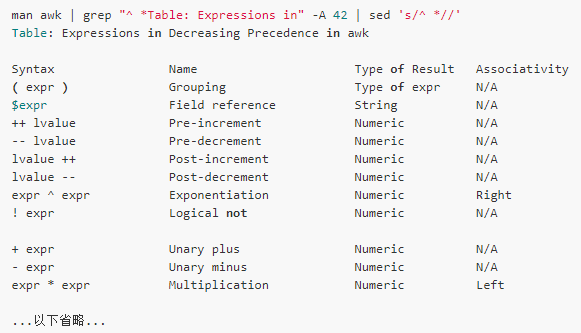
Statement
So far, the more used statements are print, others are printf, delete, break, continue, exit, next, and so on. These statements differ from functions in that they do not use parenthesized arguments and have no return value. However, there are also accidents, such as printf can be called like a function:

The break and continue statements should be well understood and used to jump out of the loop and jump to the next loop.
Delete is used to delete an element in an array, which we also used when introducing ARGV above.
The use of exit, as the name suggests, is to exit the awk process, and then execute the contents of the END section:

The next statement is similar to the sed n command, which reads the next record and returns to the beginning of the script:

It can be seen from the above that the print statement after next will not be executed.
The print and printf statements are the most used, and they output the content to standard output. Note that in the print statement, there is a difference between the output variables without a comma:
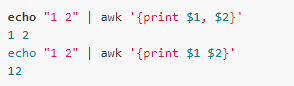
When the print is output, the separator between the fields can be redefined by OFS:

In addition to this, the output of print can also be redirected to a file or a command:

Suppose there is a file like this, the first column is the name of the statement, and the second column is the corresponding description:
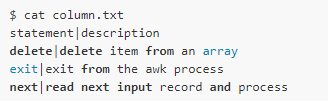
Now we need to output the contents of the two columns to the two files: statement.txt and description.txt:
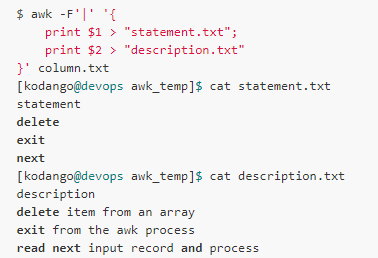
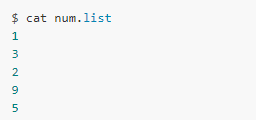
Below is an example of a redirect to a command, assuming we want to sort the following files:
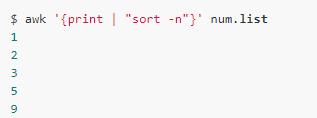
You can redirect the contents of the print to the "sort -n" command:
The printf command is similar to print, and can be redirected to a file or output, except that printf has more formatting strings than print. The syntax of printf is similar to most languages ​​including bash's printf command, which is not covered here.
Mathematical function
The following math functions are supported in awk:
Atan2(y,x): arctangent function;
Cos(x): cosine function;
Sin(x): sine function;
Exp(x): a natural logarithm e as the base exponential function;
Log(x): Calculate the logarithm of e as the base;
Sqrt(x): square root function;
Int(x): converts the value to an integer (absolute value);
Rand(): returns a random value from 0 to 1, not including 1;
Srand([expr]): Sets the random seed, which is generally used in conjunction with the rand function. If the parameter is empty, the current time is used as the seed by default;
For example, we use the rand() function to generate a random number:
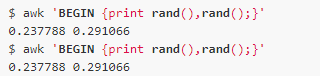
But you will find that each awk execution will generate the same random number, but the random number generated in one execution is different. Because the same seed is used every time awk is executed, we can use the srand() function to set the seed:

This way the random number generated each time is different.
We can also generate integers from 1 to n using the rand() function:

String function
Awk contains most common string manipulation functions.
Sub
Sub(ere, repl[, in])
Description: Simply put, replace the part of in in that matches ere with repl, and the return value is the number of replacements. If the in parameter is omitted, $0 is used by default. The replaced action directly modifies the value of the variable.
Here's an example of a simple replacement:

In the repl parameter & is a metacharacter that indicates the content of the match, for example:

Gsub
Gsub(ere, repl[, in])
Description: Similar to the sub() function, except that gsub() is a global replacement, which replaces all matching content.
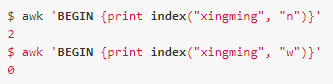
Index
Index(s, t)
Description: Returns the position where the string t appears in s. Note that the position is calculated from 1 and returns 0 if it is not found.
E.g:
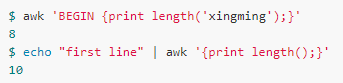
Length
Length[([s])]
Description: Returns the length of the string. If the parameter s is not specified, $0 is used as the parameter by default.
E.g:
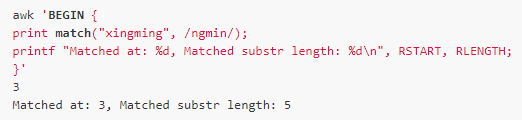
Match
Match(s, ere)
Description: Returns the starting position of the string s matching ere, or 0 if it does not match. This function defines two built-in variables, RSTART and RLENGTH. RSTART is the same as the return value, and the RLENGTH record matches the length of the substring, or -1 if it does not match.
E.g:
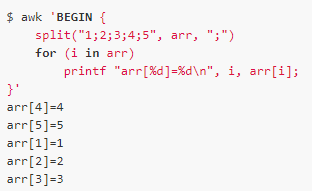
Split
Split(s, a[, fs])
Description: Separates the string into multiple parts according to the separator fs and stores it in array a. Note that the location is stored starting with the first array element. If fs is empty, FS separation is used by default. The function returns the number of values ​​separated.
E.g:
The strange thing here is that the array of for..in.. output is not output in order. If you want to output in order, you can use the regular for loop:

Sprintf
Sprintf(fmt, expr, expr, ...)
Description: Similar to printf, except that the formatted content is not output to standard output, but is returned as a return value.
E.g:

Substr
Substr(s, m[, n])
Description: Returns a substring of length n starting at position m, where the position is calculated from 1. If n is not specified or the value of n is greater than the number of remaining characters, the substring is up to the end of the string.
E.g:
Tolower
Tolower(s)
Description: Converts a string to lowercase characters.
E.g:

Toupper
Toupper(s)
Description: Converts a string to uppercase characters.
E.g

I/O handler
Getline
The usage of getline is relatively complicated, and it has several different forms. But its main role is to get one line of input each time from the input.
Expression | getline [var]
This form takes the result of the previous pipe front command output as input to getline, one line at a time. If followed by var, the contents of the read are saved to the var variable, otherwise $0 and NF will be reset.
For example, we display the contents of the above statement.txt file as input to getline:
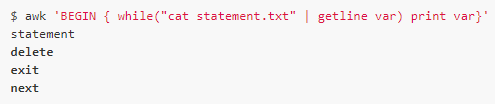
In the above example, the command uses double quotes, cat statement.txt, which is the same as print/printf.
If you do not add var, write directly to $0, note that the NF value will also be updated:
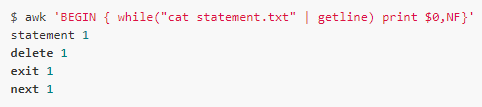
Getline [var]
The second form is to use getline directly, which reads the input from the processed file. Similarly, if var does not, $0 will be set and NF, NR and FNR will be updated at this time:
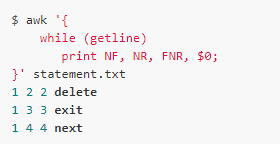
Getline [var] < expression
The third form redirects input from expression, similar to the first method, and is not described here.
Close
The close function can be used to close a file or pipe that has already been opened. For example, the first form of the getline function uses a pipe. We can close the pipe with the close function. The parameters of the close function are the same as those of the pipe:
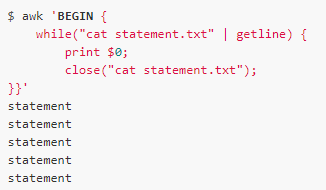
But after reading one line each time, closing the pipe, then reopening and re-reading the first line will end the loop. Therefore, it should be used with caution. In general, the close function is rarely used.
System
This function is very simple and is used to execute external commands, for example:

Conclusion
A quick look at the Awk series of articles is relatively rough, I refer to Awk's man page and "Sed & Awk" Appendix B, but should allow you to have a general understanding of awk, welcome everyone to communicate.
Buy the VapeSoul Soul Smile II Disposable Vape Device. Featuring a 550mAh internal rechargeable battery and a 5.0ml capacity of Nicotine Salt e-liquid. Hermetically sealed with silicone on the inner juice reservoir section and anti-leak cotton on the mouthpiece section, the Soul Smile 2 II can offer users a leakless vaping experience.
Outfitted with a 550mAh internal rechargeable battery and a USB port on the base, users can fuel up the device at any time with ease.
Specifications:
1500 Puffs
5ml Capacity
Cotton Coil
Battery: 550mAh
USB Charging Port
Rubber Oil Coating
Category: Dab Pen&Wax Pens
Included:
VapeSoul Soul Smile II 5ML 1500 Puffs 600mAh Rechargeable Prefilled Synthetic Nicotine Disposable Vape

Vapesoul 1500 puffs,low price vapesoul,vapesoul flavors,Vapesoul Smile II Vape
Shenzhen Kester Technology Co., Ltd , https://www.kesterpuff.com